
With this tutorial, we will learn the complete process to install Apache Spark 3.2.0 on Ubuntu 20.
Prerequisite:
Spark runs on Java 8/11, Scala 2.12, Python 3.6+ and R 3.5+. Python 3.6 support is deprecated as of Spark 3.2.0. Java 8 prior to version 8u201 support is deprecated as of Spark 3.2.0. For the Scala API, Spark 3.2.0 uses Scala 2.12. You will need to use a compatible Scala version (2.12.x).
Steps for Installing Apache Spark
Step 1 – Create a directory for example
$mkdir /home/bigdata/apachespark

Step 2 – Move to Apache Spark directory
$cd /home/bigdata/apachespark
Step 3 – Download Apache Spark (Link will change with respect to country so please get the download link from Apache Spark website ie https://spark.apache.org/downloads.html)
https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz
$wget https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz
Step 4 – Extract this tar file
$tar -xzf spark-3.2.0-bin-hadoop3.2.tgz

Step 5 – Open the bashrc files in the nano editor using the following command:
nano .bashrc
edit .bashrc file located in the user’s home directory and add the following parameters:
export SPARK_HOME=/home/bigdata/apachespark/spark-3.2.0-bin-hadoop3.2
export PATH=$PATH:$SPARK_HOME/bin

Now load the environment variables to the opened session by running the below command
source ~/.bashrc

Spark comes with several sample programs. Scala, Java, Python and R examples are in the examples/src/main directory. To run one of the Java or Scala sample programs, use bin/run-example [params] in the top-level Spark directory. (Behind the scenes, this invokes the more general spark-submit script for launching applications). For example,
$run-example SparkPi 10
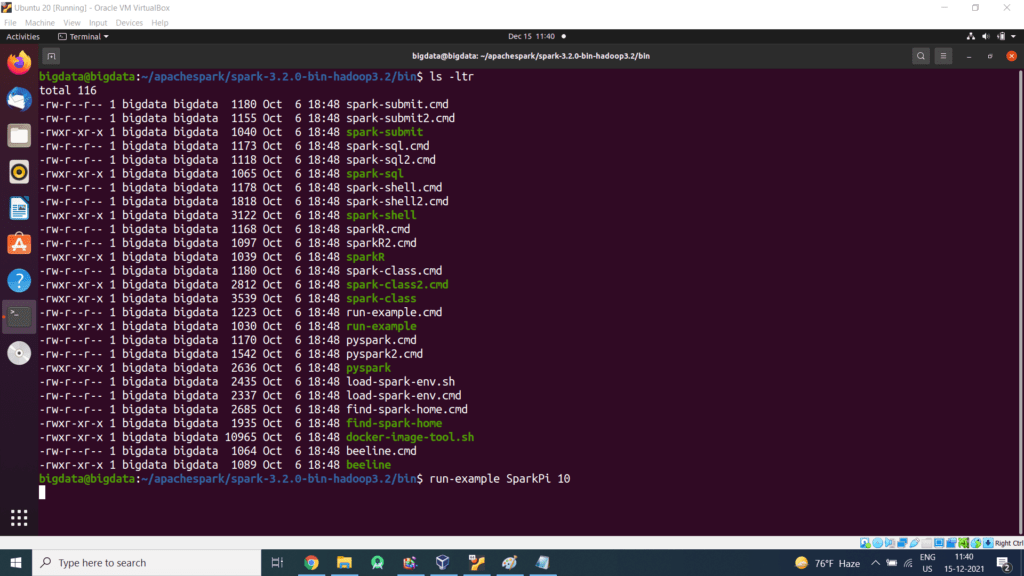


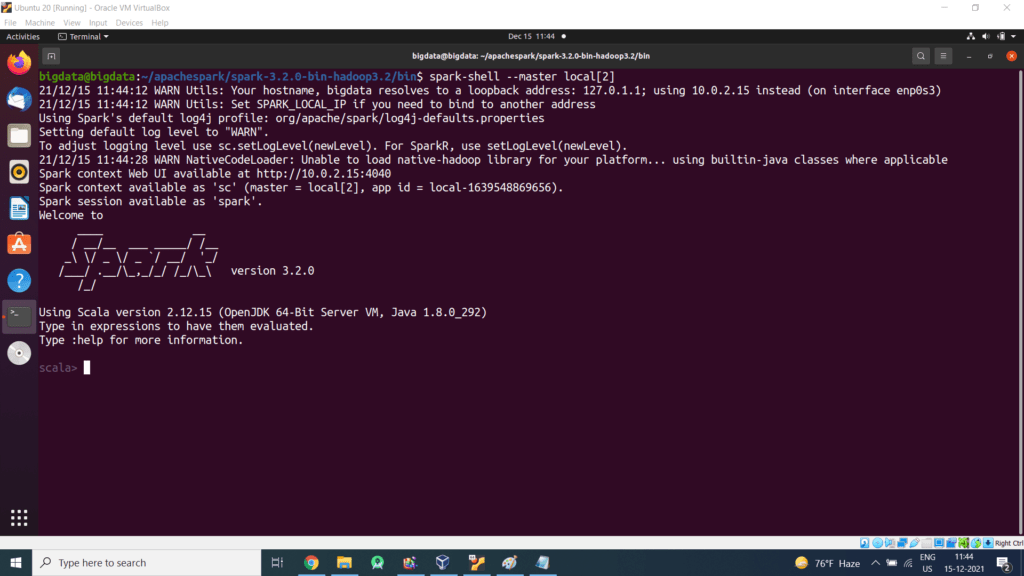
You can also run Spark interactively through a modified version of the Scala shell. This is a great way to learn the framework.
./bin/spark-shell –master local[2]
The –master option specifies the master URL for a distributed cluster, or local to run locally with one thread, or local[N] to run locally with N threads. You should start by using local for testing. For a full list of options, run Spark shell with the –help option.
Spark Web UI
Open Internet Explorer and type the below URL for Spark Web UI
http://localhost:4040

