
In this article, We will analyze Consumer Complains recorded by US government from US citizens about financial products and services using Big Data Technology, We will see step by step process execution of the project.

Problem Statement: Analyze the data in Hadoop Eco-system to:
- Get the number of complaints filed for each company.
- Get the number of complaints filed under each product.
- Get the total number of complaints filed from a particular location
- Get the list of company grouped by location which has no timely response.
Attribute Information or Dataset Details:
| Columns |
|---|
| Complaint ID |
| Product |
| Sub-product |
| Issue |
| Sub-issue |
| State |
| ZIP code |
| Submitted via |
| Date received |
| Date sent to company |
| Company |
| Company response |
| Timely response |
| Consumer disputed |

Data: Input Format – .CSV
Public DATASET available at below website
https://catalog.data.gov/dataset/consumer-complaint-database
(Note: Original data contains some additional commas we need to remove those commas)
Technology Used
- Apache Hadoop (HDFS)
- Apache Pig
- Apache Hive
- Shell Script
- Microsoft Excel
- Linux
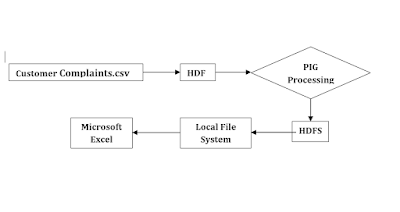
Flow Chart – Processing Logic (Customer Complaints data in Hadoop Echo System)
Apache Pig Script
Apache Pig Script purpose it to address the below Problem
- Get the number of complaints filed for each company.
- Get the number of complaints filed under each product.
- Get the total number of complaints filed from a particular location
- Get the list of company grouped by location which has no timely response
Four Output files will be created.
Apache Pig Code – Customer_Complain_Analysis.pig
CUSTOMER_COMPLAIN = LOAD '/hdfs/bhavesh/POC/Consumer_Complaints1.csv' using PigStorage(',') as (Complain_id:int, Product:chararray, Sub_Product:chararray, Issue:chararray, Sub_Issue:chararray, State:chararray, Zip:int, Submitted_via:chararray, Date_Received:chararray, Date_Sent_To_Company:chararray, Company:chararray, Company_Response:chararray, Timely_Responsesponse:chararray, Customer_Dispute:chararray);
GRP_COMPANY = GROUP CUSTOMER_COMPLAIN by Company;
CNT_COMPANY = FOREACH GRP_COMPANY GENERATE group,COUNT(CUSTOMER_COMPLAIN);
STORE CNT_COMPANY INTO '/hdfs/bhavesh/POC/Complains_by_Company/' using PigStorage(',');
GRP_PRODUCT = GROUP CUSTOMER_COMPLAIN by Product;
CNT_PRODUCT = FOREACH GRP_PRODUCT GENERATE group,COUNT(CUSTOMER_COMPLAIN);
STORE CNT_PRODUCT INTO '/hdfs/bhavesh/POC/Complains_by_Product/' using PigStorage(',');
GRP_LOCATION = GROUP CUSTOMER_COMPLAIN by State;
CNT_LOCATION = FOREACH GRP_LOCATION GENERATE group,COUNT(CUSTOMER_COMPLAIN);
STORE CNT_LOCATION INTO '/hdfs/bhavesh/POC/Complains_by_Location/' using PigStorage(',');
FLTR_TIME_RESPONSE = FILTER CUSTOMER_COMPLAIN by Timely_Responsesponse=='No';
GRP_COMPANY_LOCATION = GROUP FLTR_TIME_RESPONSE by State;
COMPANY_AND_LOCATION = FOREACH GRP_COMPANY_LOCATION GENERATE group,FLATTEN(FLTR_TIME_RESPONSE.Company);
STORE COMPANY_AND_LOCATION INTO '/hdfs/bhavesh/POC/Complains_by_Response_No/' using PigStorage(',');Shell Script
Purpose of this shell script is to perform cleanup (delete existing output files) and execute the Pig Script to get Customer Complaints Analysis and store the resultant file in CSV format.
Shell Script Code – Customer_Complain_Analysis.sh
rm /home/mrinmoy/Downloads/POC/Complains_by_Company.csv rm /home/mrinmoy/Downloads/POC/Complains_by_Product.csv rm /home/mrinmoy/Downloads/POC/Complains_by_Location.csv rm /home/mrinmoy/Downloads/POC/Complains_by_Response_No.csv hadoop fs -rmr /hdfs/bhavesh/POC/Complains_by_Company hadoop fs -rmr /hdfs/bhavesh/POC/Complains_by_Product hadoop fs -rmr /hdfs/bhavesh/POC/Complains_by_Location hadoop fs -rmr /hdfs/bhavesh/POC/Complains_by_Response_No pig /home/bhavesh/POC/Customer_Complain_Analysis.pig hadoop fs -get /hdfs/bhavesh/POC/Complains_by_Company/part-r-00000 /home/mrinmoy/Downloads/POC/Complains_by_Company.csv hadoop fs -get /hdfs/bhavesh/POC/Complains_by_Product/part-r-00000 /home/mrinmoy/Downloads/POC/Complains_by_Product.csv hadoop fs -get /hdfs/bhavesh/POC/Complains_by_Location/part-r-00000 /home/mrinmoy/Downloads/POC/Complains_by_Location.csv hadoop fs -get /hdfs/bhavesh/POC/Complains_by_Response_No/part-r-00000 /home/mrinmoy/Downloads/POC/Complains_by_Response_No.csv
