
Movies are loved by everyone irrespective of age, gender, race, color, or geographical location. A recommendation system is a filtration program whose prime goal is to predict the “rating” or “preference” of a user towards a domain-specific item or item. Recommendation systems encompass a class of techniques and algorithms that can suggest “relevant” items to users. They predict future behavior based on past data through a multitude of techniques.
Problem Statement or Business Problem
In this project, we will generate top 10 movie recommendations for each user as well as generate top 10 user recommendations for each movie.
Attribute Information or Dataset Details:
- UserID
- MovieID
- Rating
- TimeStamp
Technology Used
- Apache Spark
- Spark SQL
- Apache Spark MLLib
- Scala
- DataFrame-based API
- Databricks Notebook
Introduction
Welcome to this project on creating Movies Recommendation Engine using Apache Spark Machine Learning using Databricks platform community edition server which allows you to execute your spark code, free of cost on their server just by registering through email id.
In this project, we explore Apache Spark and Machine Learning on the Databricks platform.
I am a firm believer that the best way to learn is by doing. That’s why I haven’t included any purely theoretical lectures in this tutorial: you will learn everything on the way and be able to put it into practice straight away. Seeing the way each feature works will help you learn Apache Spark machine learning thoroughly by heart.
We’re going to look at how to set up a Spark Cluster and get started with that. And we’ll look at how we can then use that Spark Cluster to take data coming into that Spark Cluster, a process that data using a Machine Learning model, and generate some sort of output in the form of a prediction. That’s pretty much what we’re going to learn about the predictive model.
In this project, we will be creating Movies Recommendation Engine that will generate top 10 movie recommendations for each user as well as generate top 10 user recommendations for each movie.
We will learn:
- Preparing the Data for Processing.
- Basics flow of data in Apache Spark, loading data, and working with data, this course shows you how Apache Spark is perfect for a Machine Learning job.
- Learn the basics of Databricks notebook by enrolling in Free Community Edition Server
- Define the Machine Learning Pipeline
- Train a Machine Learning Model
- Testing a Machine Learning Model
- Evaluating a Machine Learning Model (i.e. Examine the Predicted and Actual Values)
- The goal is to provide you with practical tools that will be beneficial for you in the future. While doing that, you’ll develop a model with a real use opportunity.
I am really excited you are here, I hope you are going to follow all the way to the end of the Project. It is fairly straight forward fairly easy to follow through the article we will show you step by step each line of code & we will explain what it does and why we are doing it.
Free Account creation in Databricks
Creating a Spark Cluster
Basics about Databricks notebook
Loading Data into Databricks Environment
Download Data
Load Data in Dataframe using User-defined Schema
We are loading Text (TXT) file into Dataframe using User Defined Schema (case class)
%scala
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.recommendation.ALS
case class Rating(userId: Int, movieId: Int, rating: Float, timestamp: Long)
def parseRating(str: String): Rating = {
val fields = str.split("::")
assert(fields.size == 4)
Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat, fields(3).toLong)
}
val ratings = spark.read.textFile("/FileStore/tables/sample_movielens_ratings.txt")
.map(parseRating)
.toDF()
ratings.show()
Output:
+------+-------+------+----------+
|userId|movieId|rating| timestamp|
+------+-------+------+----------+
| 0| 2| 3.0|1424380312|
| 0| 3| 1.0|1424380312|
| 0| 5| 2.0|1424380312|
| 0| 9| 4.0|1424380312|
| 0| 11| 1.0|1424380312|
| 0| 12| 2.0|1424380312|
| 0| 15| 1.0|1424380312|
| 0| 17| 1.0|1424380312|
| 0| 19| 1.0|1424380312|
| 0| 21| 1.0|1424380312|
| 0| 23| 1.0|1424380312|
| 0| 26| 3.0|1424380312|
| 0| 27| 1.0|1424380312|
| 0| 28| 1.0|1424380312|
| 0| 29| 1.0|1424380312|
| 0| 30| 1.0|1424380312|
| 0| 31| 1.0|1424380312|
| 0| 34| 1.0|1424380312|
| 0| 37| 1.0|1424380312|
| 0| 41| 2.0|1424380312|
+------+-------+------+----------+
only showing top 20 rowsSplit the Data
It is common practice when building machine learning models to split the source data, using some of it to train the model and reserving some to test the trained model. In this project, you will use 80% of the data for training, and reserve 20% for testing.
%scala val Array(training, test) = ratings.randomSplit(Array(0.8, 0.2)) Output: training:org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [userId: integer, movieId: integer ... 2 more fields] test:org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [userId: integer, movieId: integer ... 2 more fields]
Create ALS Model on Training Data
We are using Collaborative Filtering, a commonly used recommender technique, to predict movie recommendations.These techniques aim to fill in the missing entries of a user-item association matrix. spark.ml currently supports model-based collaborative filtering, in which users and products are described by a small set of latent factors that can be used to predict missing entries. spark.ml uses the alternating least squares (ALS) algorithm to learn these latent factors.
%scala
// Build the recommendation model using ALS on the training data
val als = new ALS()
.setMaxIter(10)
.setRegParam(0.01)
.setUserCol("userId")
.setItemCol("movieId")
.setRatingCol("rating")
val model = als.fit(training)
Output:
als: org.apache.spark.ml.recommendation.ALS = als_9ad10d8ed65d
model: org.apache.spark.ml.recommendation.ALSModel = ALSModel: uid=als_9ad10d8ed65d, rank=10
// Evaluate the model by computing the RMSE on the test data
// Note we set cold start strategy to 'drop' to ensure we don't get NaN evaluation metrics
model.setColdStartStrategy("drop")
val predictions = model.transform(test)
Output:
predictions: org.apache.spark.sql.DataFrame = [userId: int, movieId: int ... 3 more fields]Evaluate the model by computing the RMSE on the test data
%scala
val evaluator = new RegressionEvaluator()
.setMetricName("rmse")
.setLabelCol("rating")
.setPredictionCol("prediction")
val rmse = evaluator.evaluate(predictions)
println(s"Root-mean-square error = $rmse")
Output:
Root-mean-square error = 1.7144787698712107
evaluator: org.apache.spark.ml.evaluation.RegressionEvaluator = RegressionEvaluator: uid=regEval_d706cdcdcf16, metricName=rmse, throughOrigin=false
rmse: Double = 1.7144787698712107Generate top 10 movie recommendations for each user
%scala // Generate top 10 movie recommendations for each user val userRecs = model.recommendForAllUsers(10) display(userRecs)

Generate top 10 user recommendations for each movie
%scala // Generate top 10 user recommendations for each movie val movieRecs = model.recommendForAllItems(10) display(movieRecs)

Generate top 10 movie recommendations for a specified set of users
%scala // Generate top 10 movie recommendations for a specified set of users val users = ratings.select(als.getUserCol).distinct().limit(3) val userSubsetRecs = model.recommendForUserSubset(users, 10) display(userSubsetRecs)
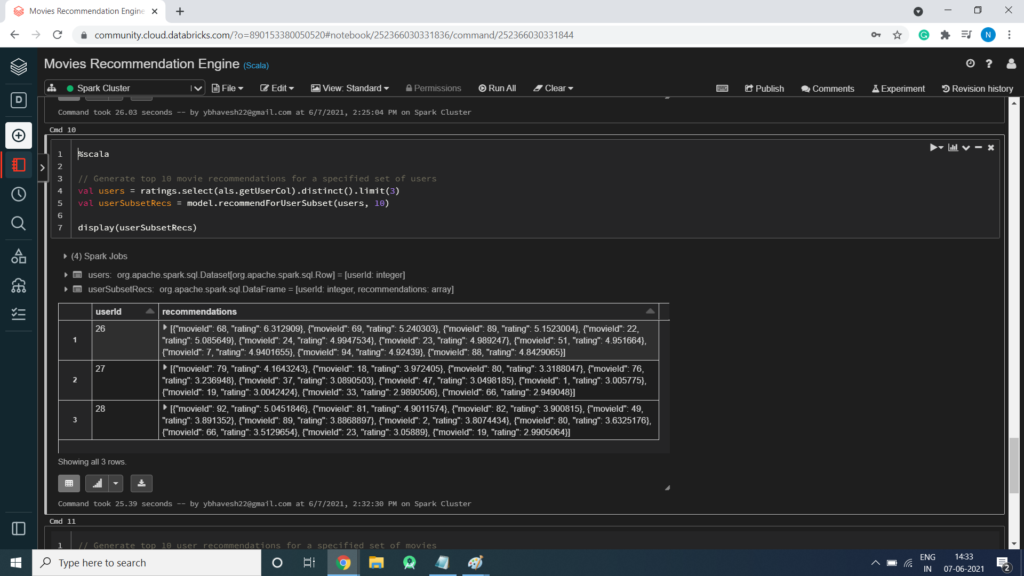
Generate top 10 user recommendations for a specified set of movies
%scala // Generate top 10 user recommendations for a specified set of movies val movies = ratings.select(als.getItemCol).distinct().limit(3) val movieSubSetRecs = model.recommendForItemSubset(movies, 10) display(movieSubSetRecs)


