
Project idea – The idea behind this Analysis project is to analysis Slack usage.
Problem Statement or Business Problem
Slack is a messaging program designed specifically for the office, but has also been adopted for personal use. Slack including persistent chat rooms (channels) organized by topic, private groups, and direct messaging. In addition to these online communication features, Slack integrates with other software.
In this tutorial we will try to analyze usage of slack software.
Technology Used
- Apache Spark
- Spark SQL
- Scala
- DataFrame-based API
- Databricks Notebook
Introduction
Welcome to this project on Slack Data Analysis in Apache Spark Analytics using Databricks platform community edition server which allows you to execute your spark code, free of cost on their server just by registering through email id.
In this project, we explore Apache Spark on the Databricks platform.
I am a firm believer that the best way to learn is by doing. That’s why I haven’t included any purely theoretical lectures in this tutorial: you will learn everything on the way and be able to put it into practice straight away. Seeing the way each feature works will help you learn Apache Spark thoroughly by heart.
We’re going to look at how to set up a Spark Cluster and get started with that. And we’ll look at how we can then use that Spark Cluster to take data coming into that Spark Cluster, a process that data, and analyze the data in Databricks platform. That’s pretty much what we’re going to learn in this tutorial.
In this project, we will be performing Slack Data Analysis
We will learn:
- Preparing the Data for Processing.
- Basics flow of data in Apache Spark, loading data, and working with data, this course shows you how Apache Spark is perfect for a Data Analysis job.
- Learn the basics of Databricks notebook by enrolling in Free Community Edition Server
The goal is to provide you with practical tools that will be beneficial for you in the future. While doing that, you’ll develop a model with a real use opportunity.
I am really excited you are here, I hope you are going to follow all the way to the end of the Project. It is fairly straight forward fairly easy to follow through the article we will show you step by step each line of code & we will explain what it does and why we are doing it.
Free Account creation in Databricks
Creating a Spark Cluster
Basics about Databricks notebook
Loading Data into Databricks Environment
Download Data
Load Data in Dataframe
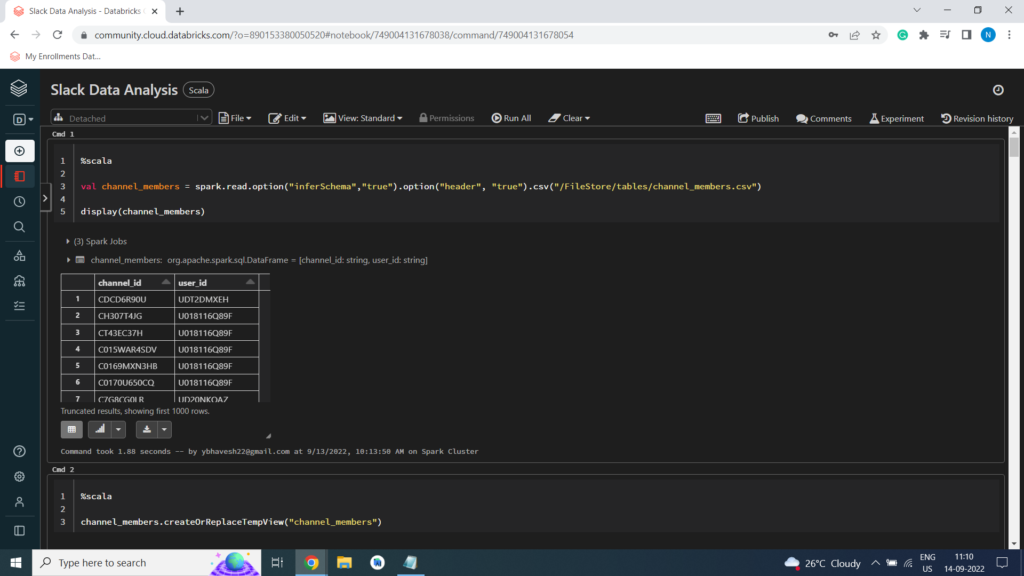
Channel Members Dataset
%scala
val channel_members = spark.read.option(“inferSchema”,”true”).option(“header”, “true”).csv(“/FileStore/tables/channel_members.csv”)
display(channel_members)
Creating Temporary View
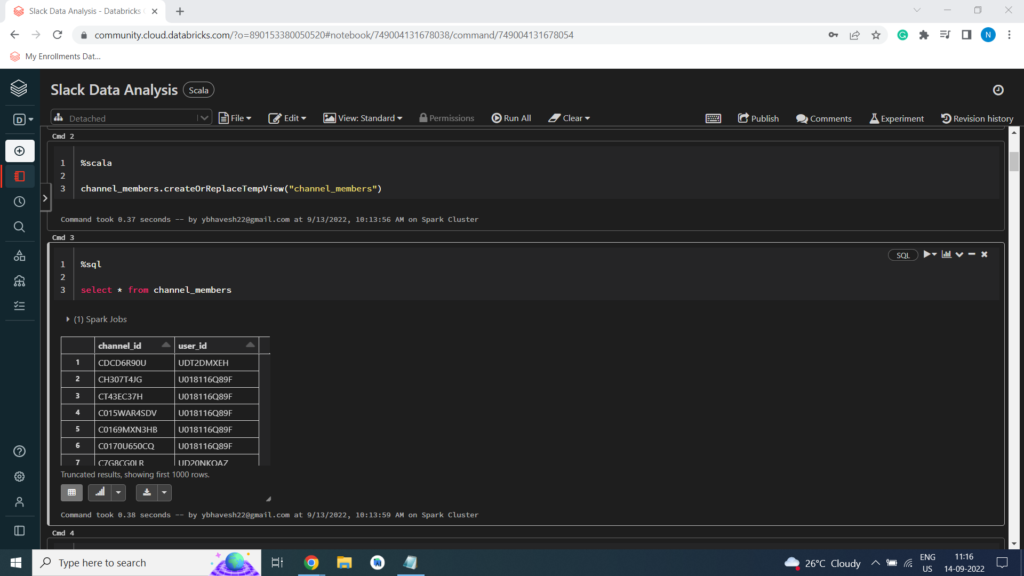
%scala
channel_members.createOrReplaceTempView(“channel_members”)
Load Data in Dataframe
Load Data in Dataframe
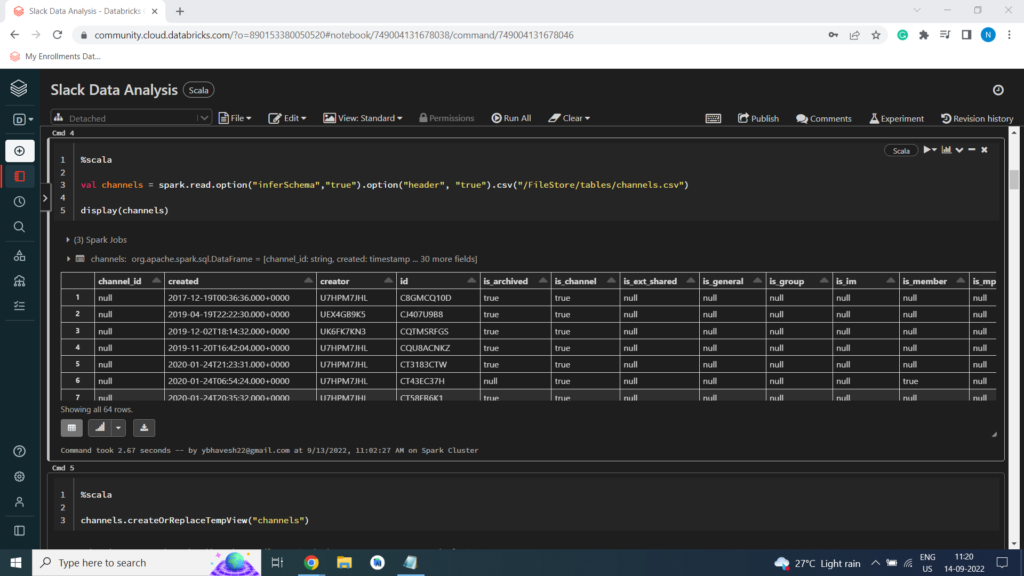
Channels Dataset
%scala
val channels = spark.read.option(“inferSchema”,”true”).option(“header”, “true”).csv(“/FileStore/tables/channels.csv”)
display(channels)
Creating Temporary View
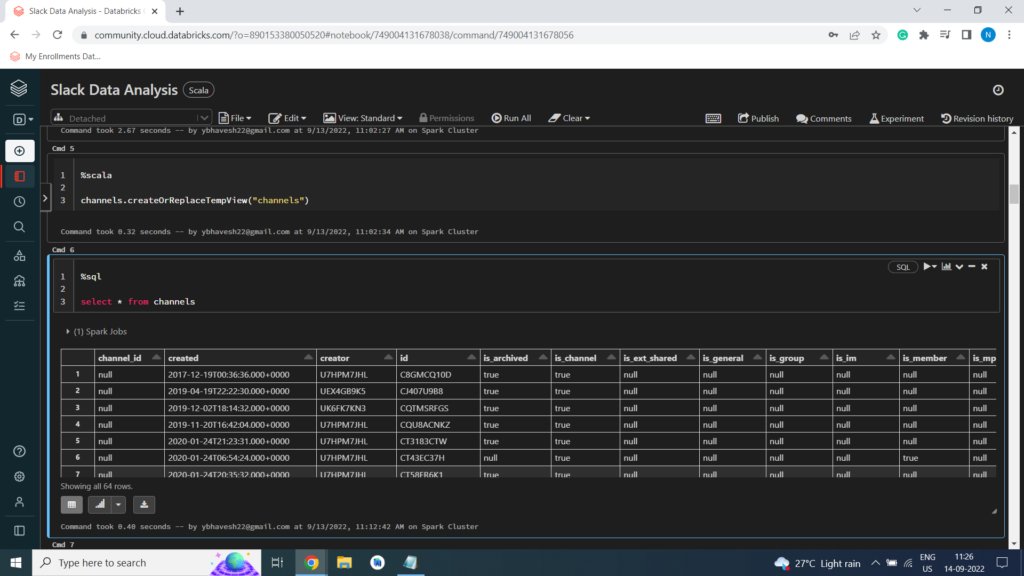
%scala
channels.createOrReplaceTempView(“channels”)
Load Data in Dataframe
Exported Stats Datasets
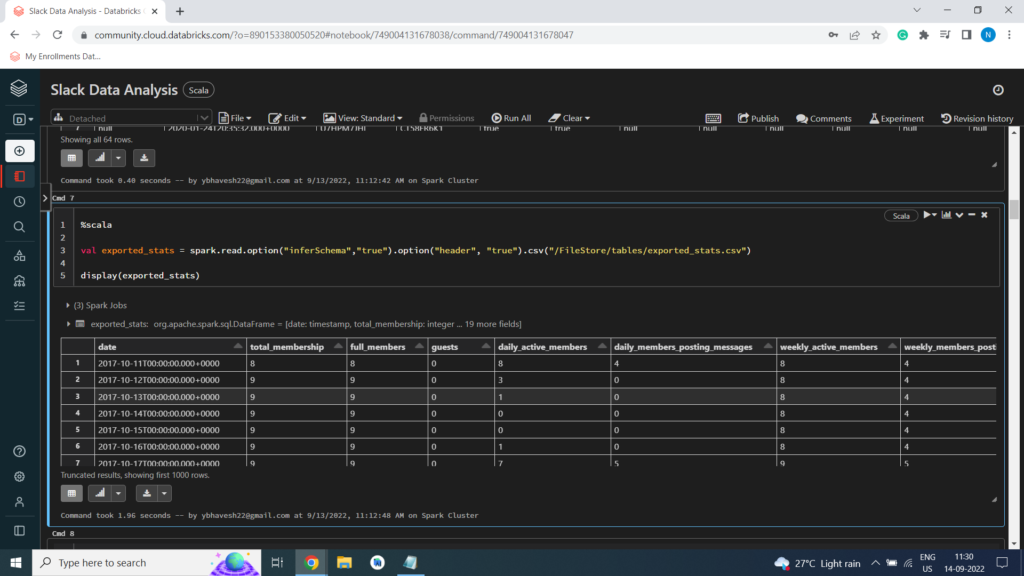
%scala
val exported_stats = spark.read.option(“inferSchema”,”true”).option(“header”, “true”).csv(“/FileStore/tables/exported_stats.csv”)
display(exported_stats)
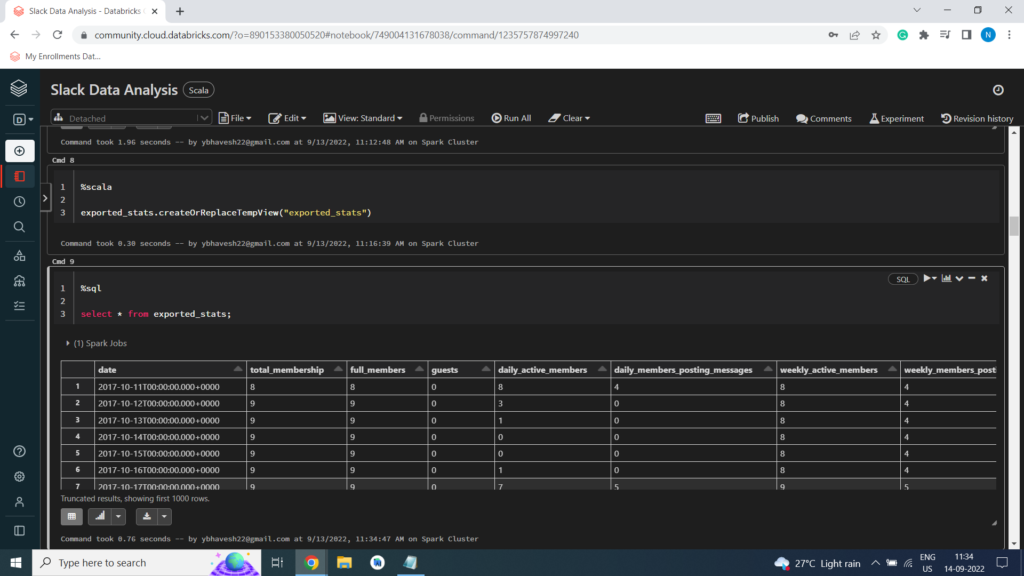
Creating Temporary View
%scala
exported_stats.createOrReplaceTempView(“exported_stats”)
Load Data in Dataframe
Load Data in Dataframe
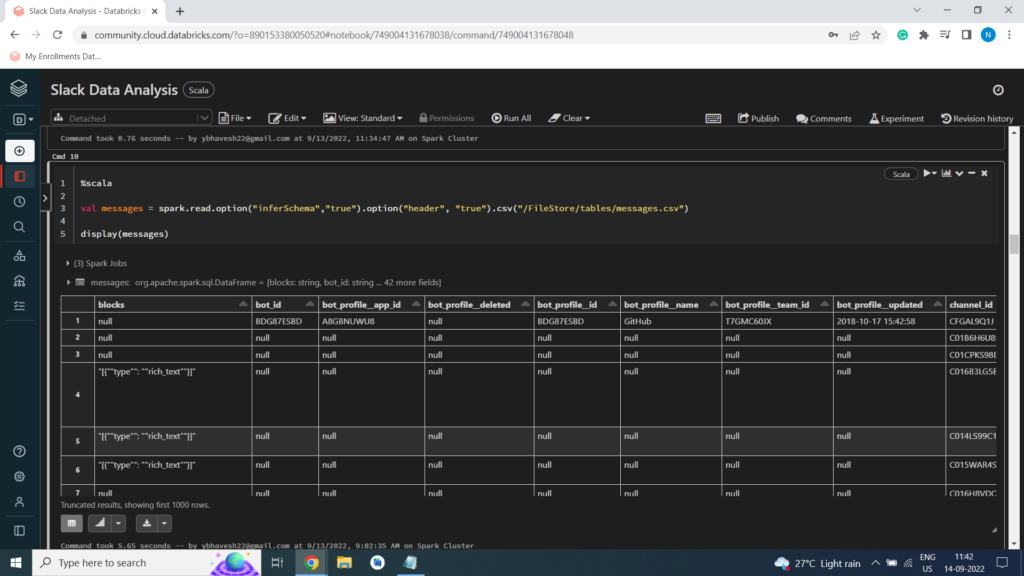
Messages Dataset
%scala
val messages = spark.read.option(“inferSchema”,”true”).option(“header”, “true”).csv(“/FileStore/tables/messages.csv”)
display(messages)
Creating Temporary View
%scala
messages.createOrReplaceTempView(“messages”)

Load Data in Dataframe
Threads Dataset
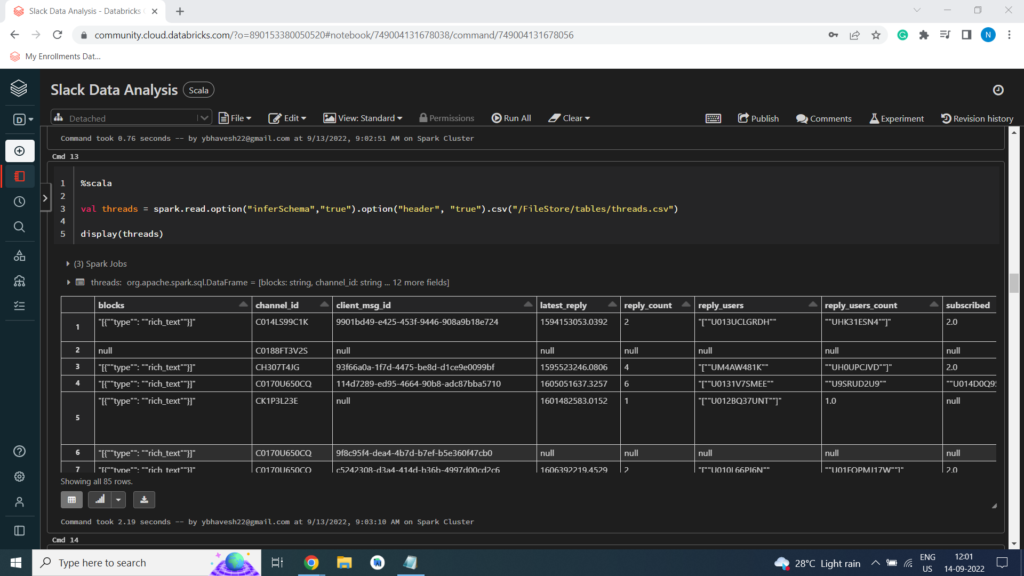
Creating Temporary View
%scala
threads.createOrReplaceTempView(“threads”)
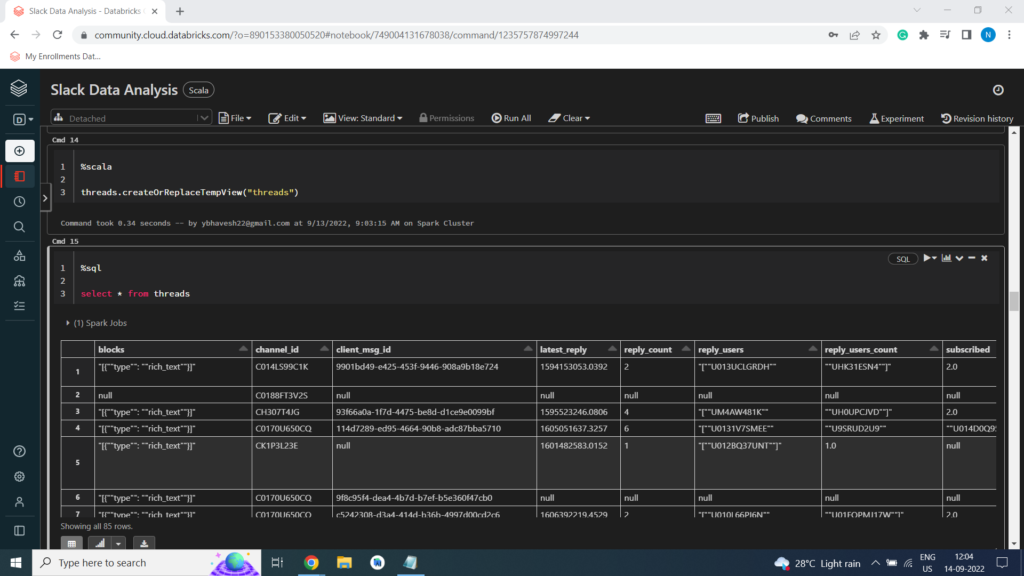
Load Data in Dataframe
Users Dataset
%scala
val users = spark.read.option(“inferSchema”,”true”).option(“header”, “true”).csv(“/FileStore/tables/users.csv”)
display(users)
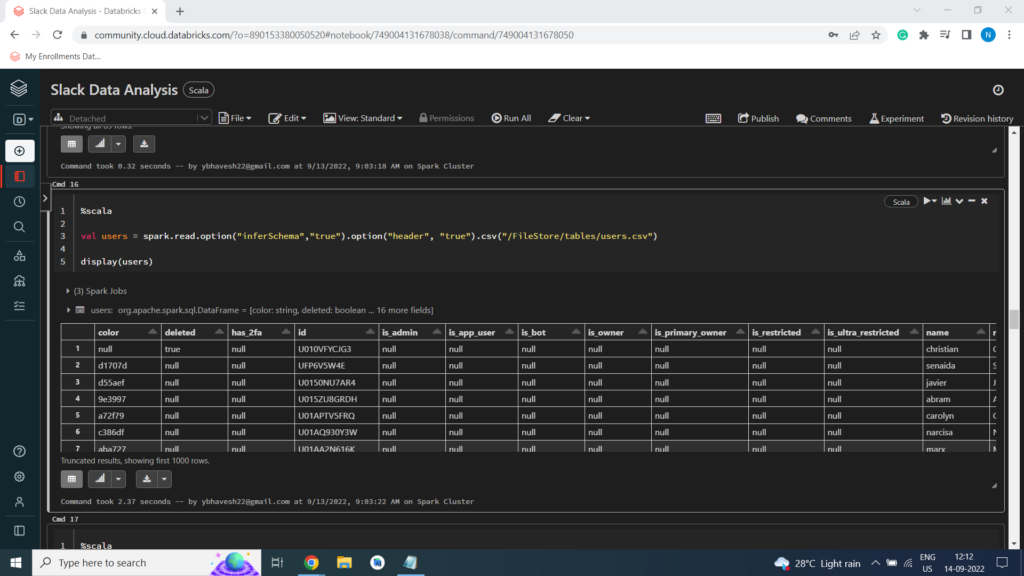
Creating Temporary View
%scala
users.createOrReplaceTempView(“users”)
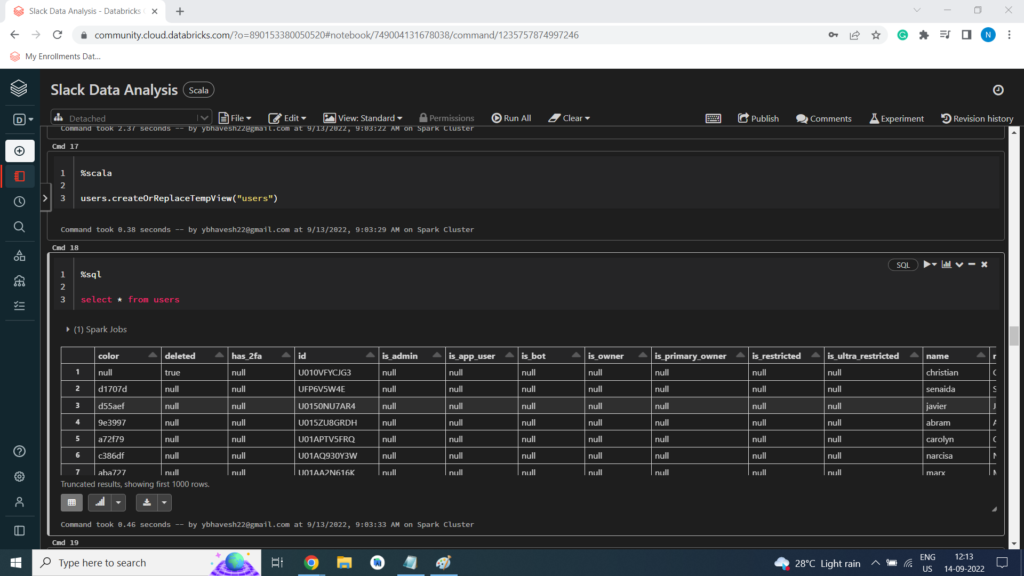
Load Data in Dataframe
Users Channels Dataset
%scala
val users_channels = spark.read.option(“inferSchema”,”true”).option(“header”, “true”).csv(“/FileStore/tables/users_channels.csv”)
display(users_channels)
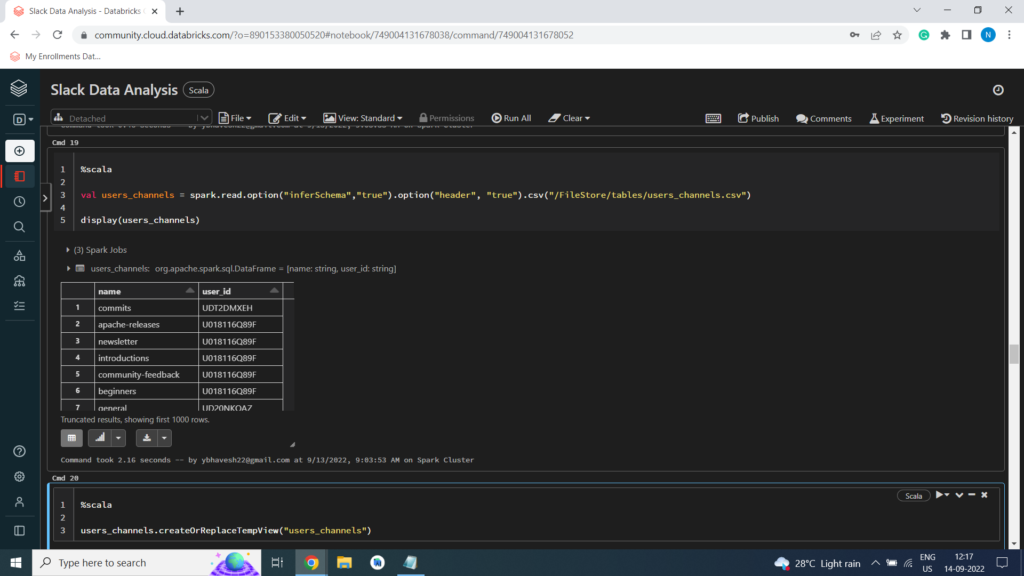
Creating Temporary View
%scala
users_channels.createOrReplaceTempView(“users_channels”)
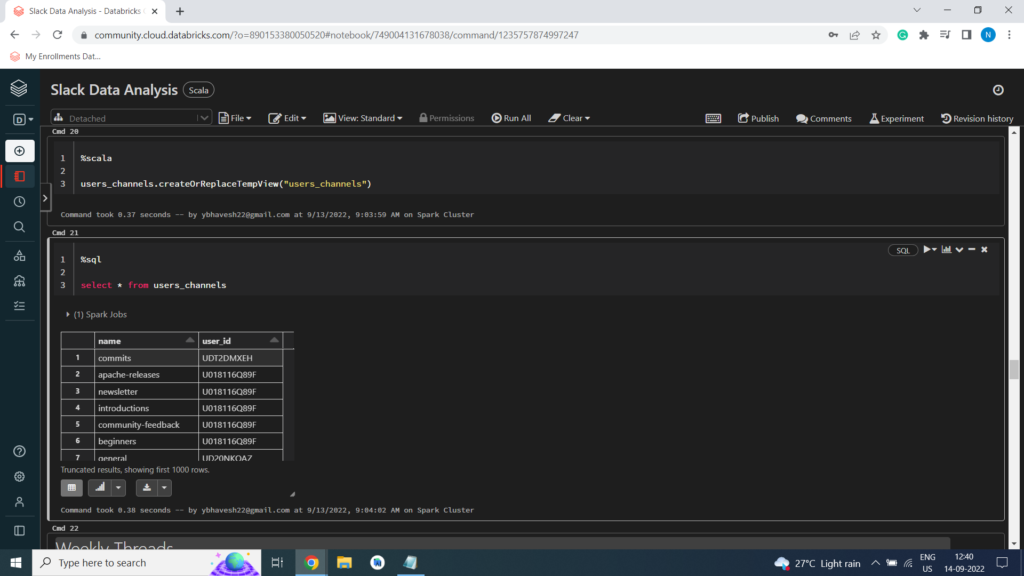
Exploratory Data Analysis or EDA
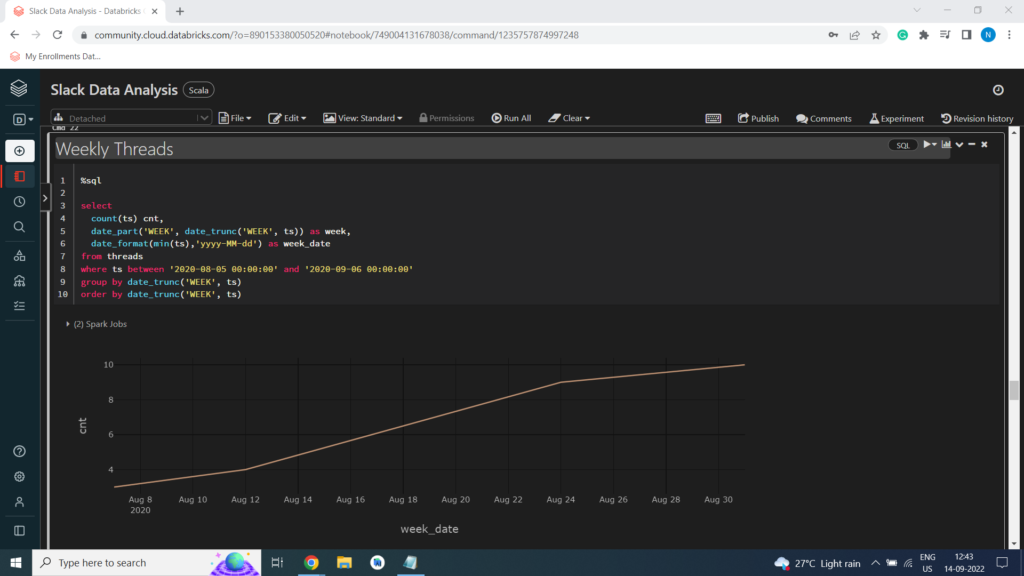
Weekly Threads
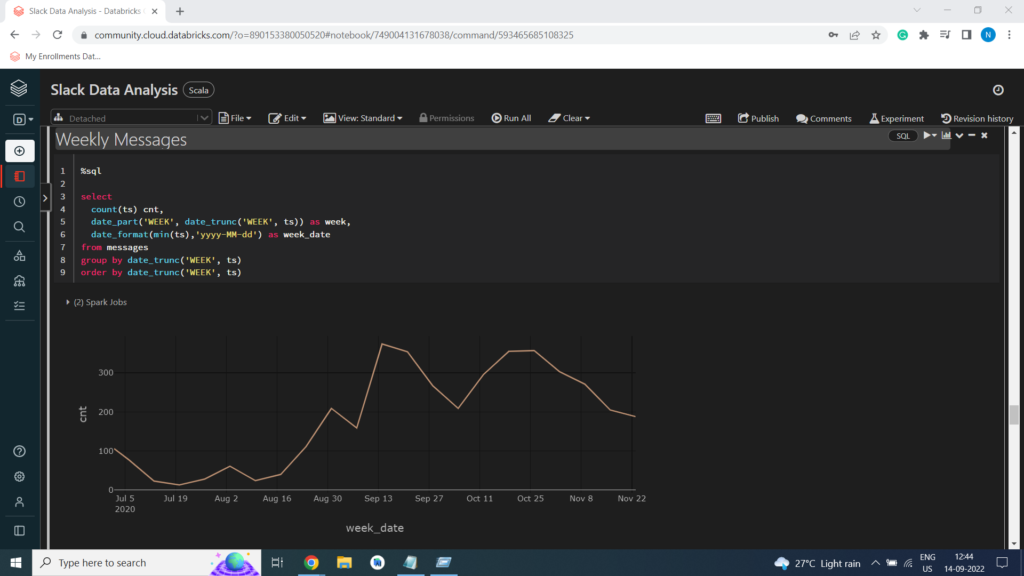
Weekly Messages
Slack Members
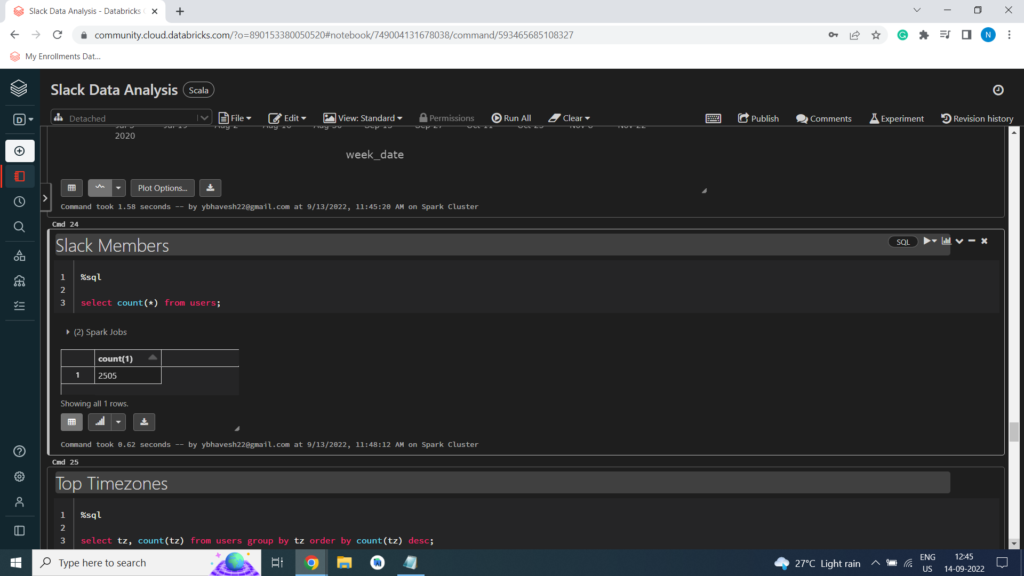
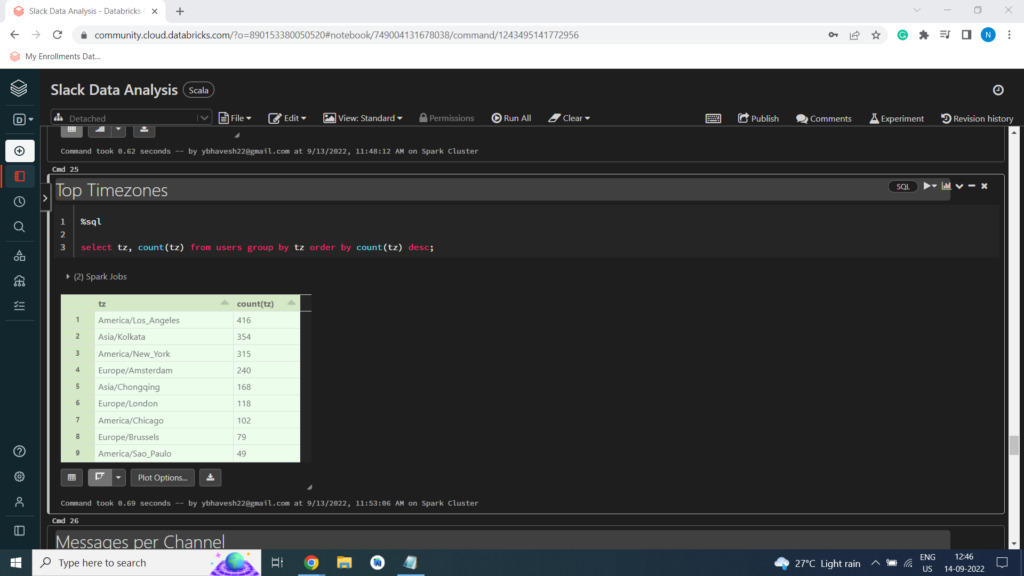
Top Timezones
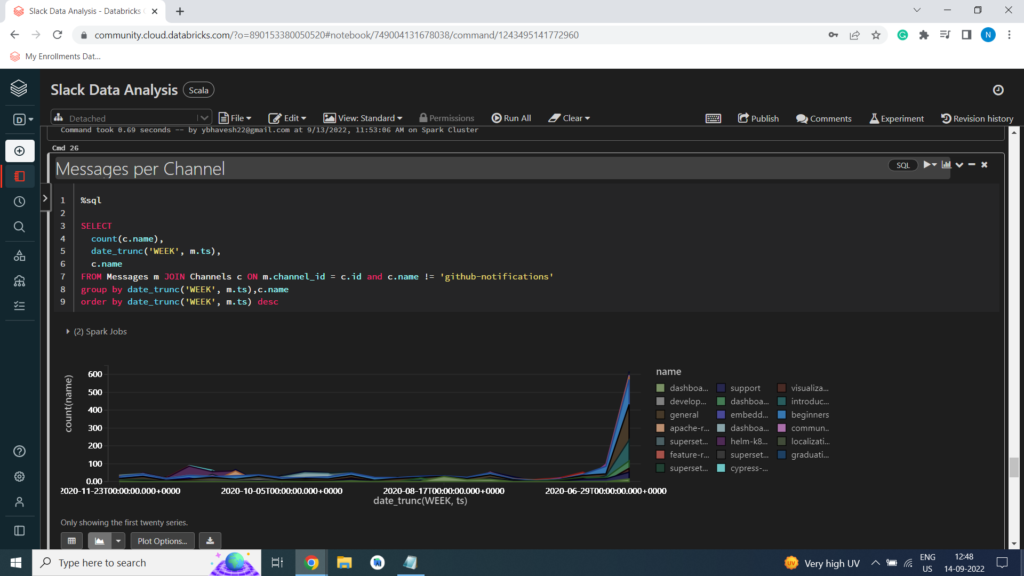
Messages per Channel
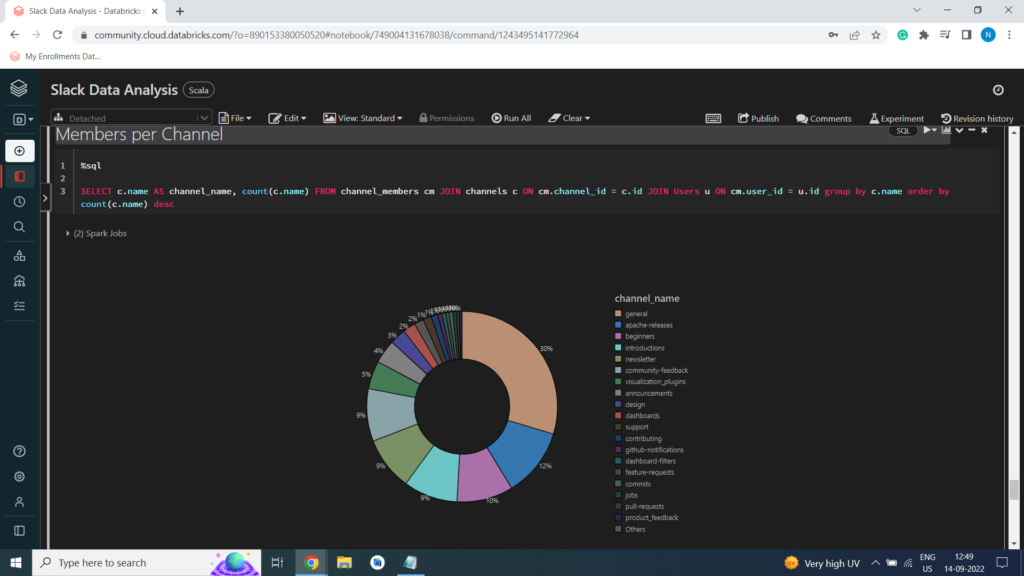
Members per Channel
Cross Channel Relationship


