
In this tutorial, we will set up a single node Spark cluster and run it in local mode using the command line.
Step 1) Let’s start getting the spark binary you can download the spark binary from the below link
- Download Spark link: https://spark.apache.org/
- Windows Utils link: https://github.com/steveloughran/winutils
Step 2) Click on Download
Step 3) A new Web page will get open
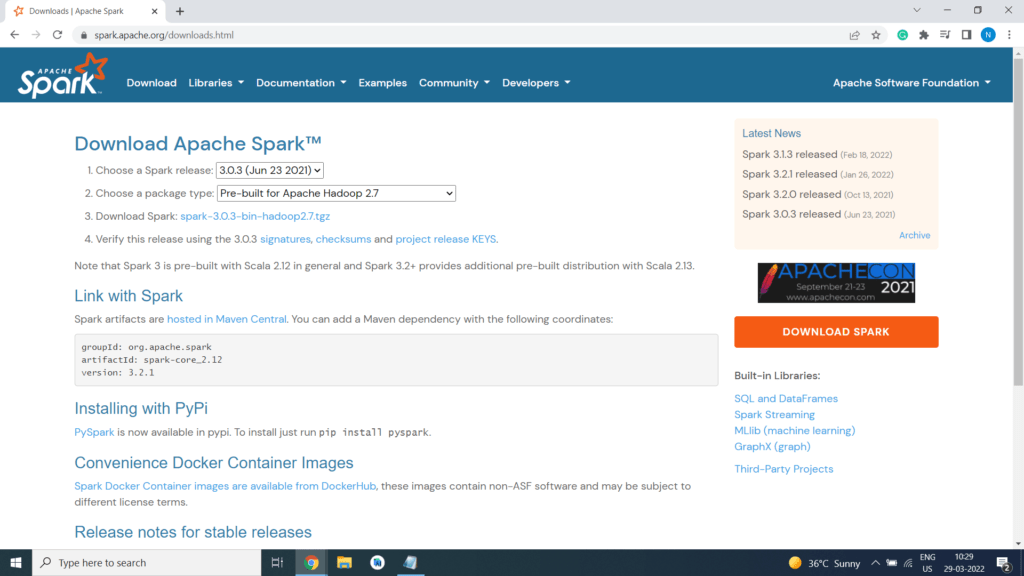
i) Choose a Spark release as 3.0.3
ii) Choose a package type as Pre-built for Apache Hadoop 2.7
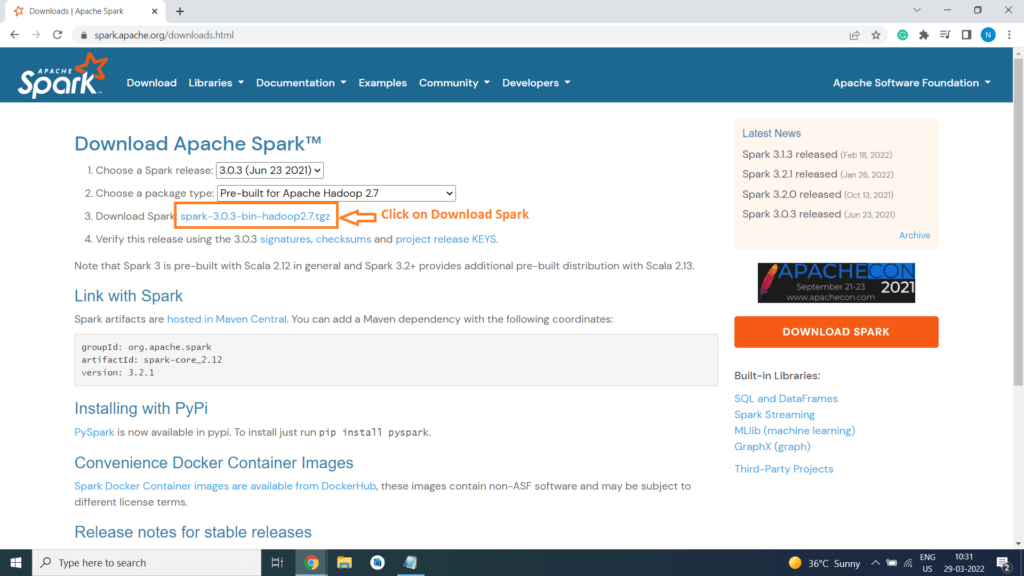
Step 4) Click on Download Spark spark-3.0.3-bin-hadoop2.7.tgz
Step 5) A new Web Page will get open
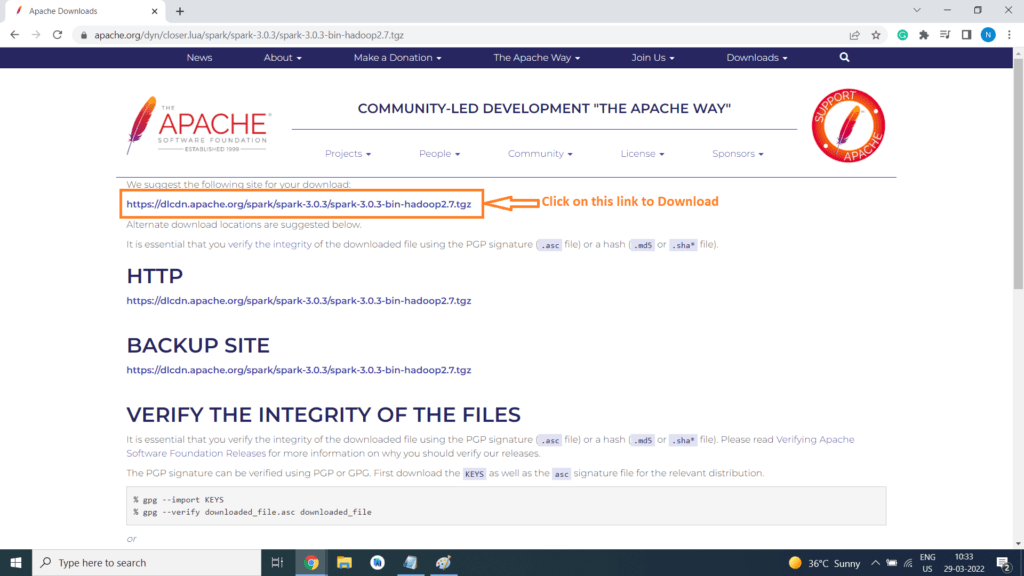
Step 6) Click on the link to download
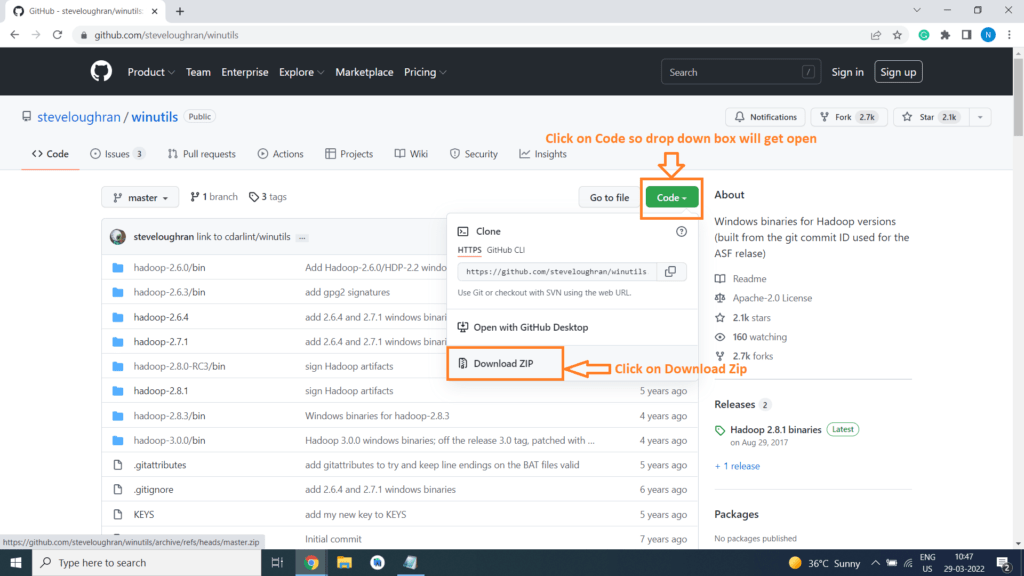
Step 7) Open the website https://github.com/steveloughran/winutils and Download the winutils
Step 8) Now our Download folder will have 2 files
i) spark-3.0.3-bin-hadoop2.7.tgz
ii) winutils-master.zip
Step 9) Choose any Drive (C: or D: or E:) where you have space I have free space in D Drive so I have created a folder Spark in D Drive

Step 10) Move the 2 Downloaded files in D:\Spark

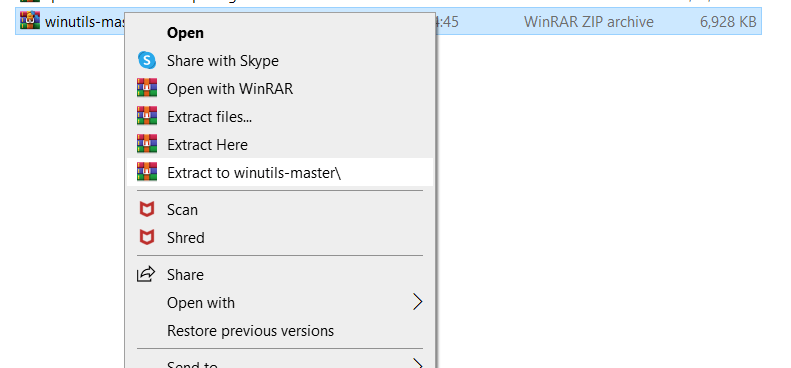
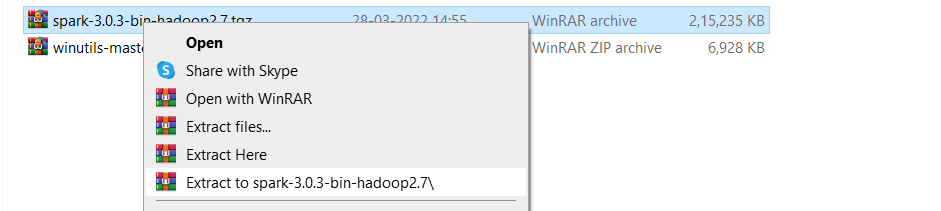
Step 11) Unzip the 2 files
i) Click on Extract to winutils-master\
ii) Click on Extract to spark-3.0.3-bin-hadoop2.7\
Step 12) We will have 2 new folders (spark-3.0.3-bin-hadoop2.7 and winutils-master)
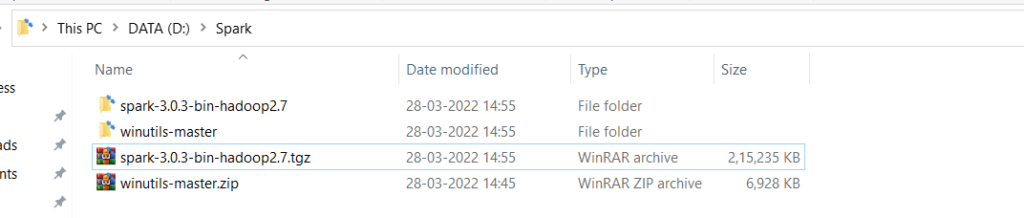
Step 13) If we go to this location D:\Spark\spark-3.0.3-bin-hadoop2.7\spark-3.0.3-bin-hadoop2.7
We have many folders
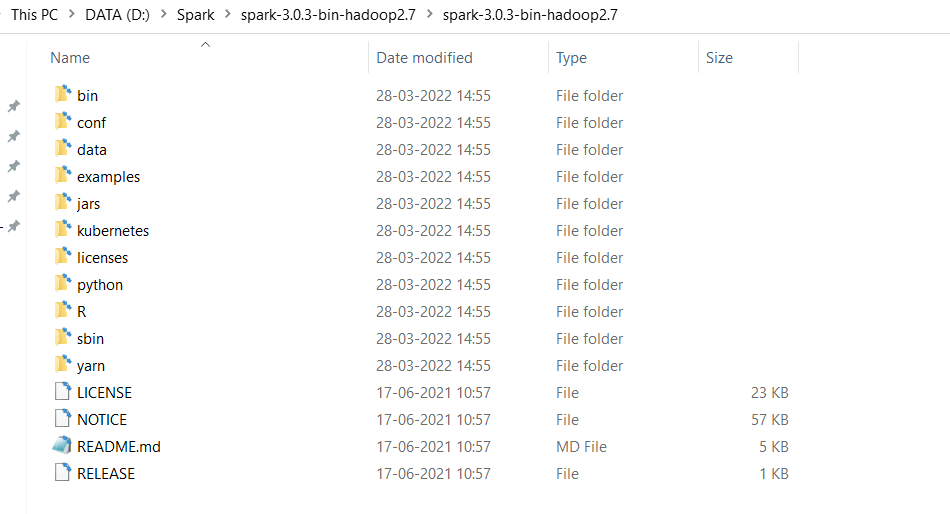
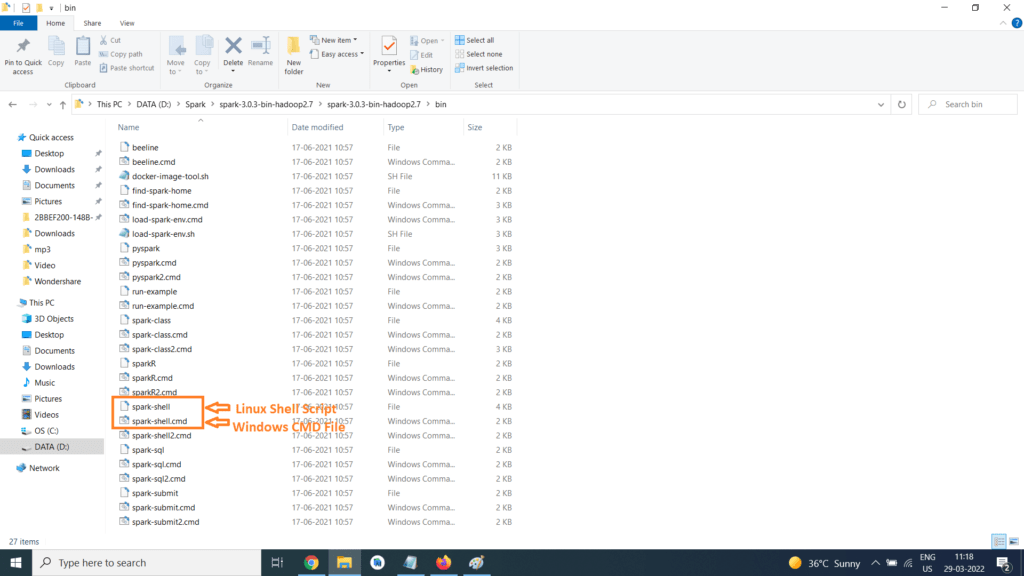
We are more interested in the bin folder so double click on the bin folder so bin folder will get open
They are 2 sets of files one for Linux and other for windows
Step 14) Type cmd on the Title bar and press enter

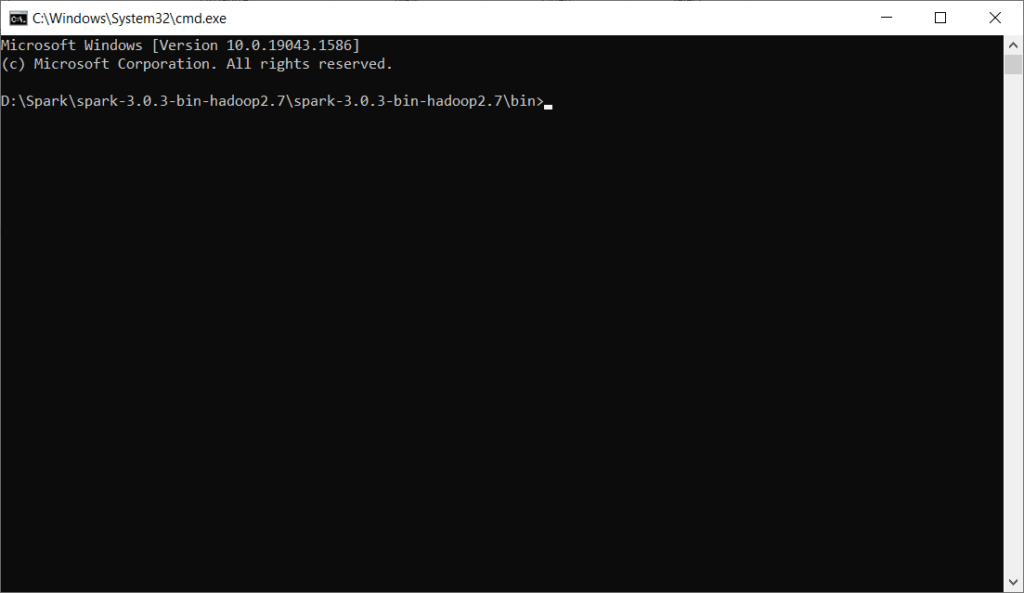
We will be in path D:\Spark\spark-3.0.3-bin-hadoop2.7\spark-3.0.3-bin-hadoop2.7\bin in command prompt
Step 15) Enter the below 2 command in command prompt
setx HADOOP_HOME “D:\Spark\winutils-master\winutils-master\hadoop-2.7.1”
setx SPARK_HOME “D:\Spark\spark-3.0.3-bin-hadoop2.7\spark-3.0.3-bin-hadoop2.7”
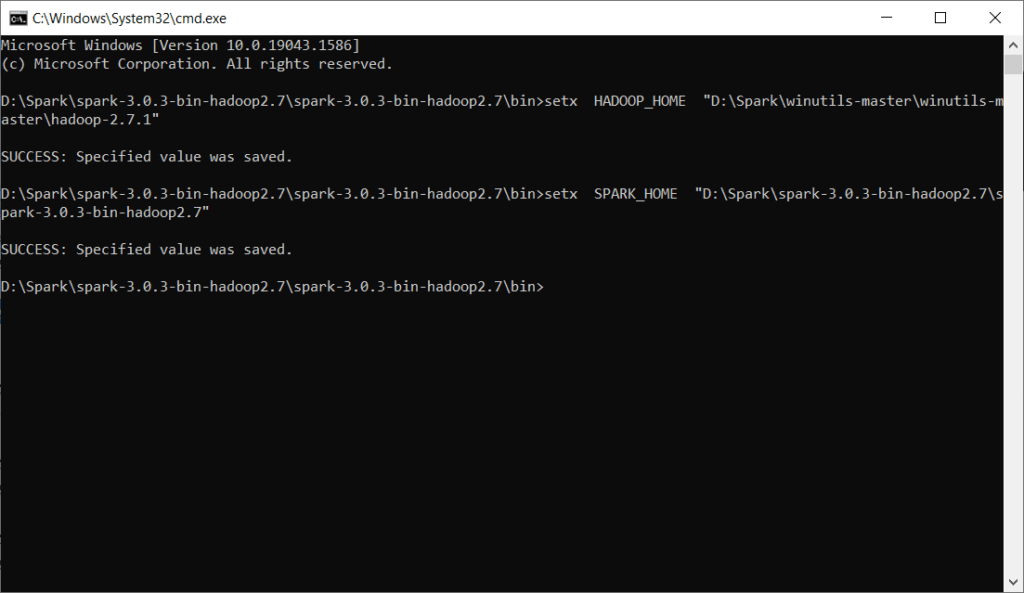
Step 16) Verify if SPARK_HOME and HADOOP_HOME is set properly
echo %HADOOP_HOME%
echo %SPARK_HOME%
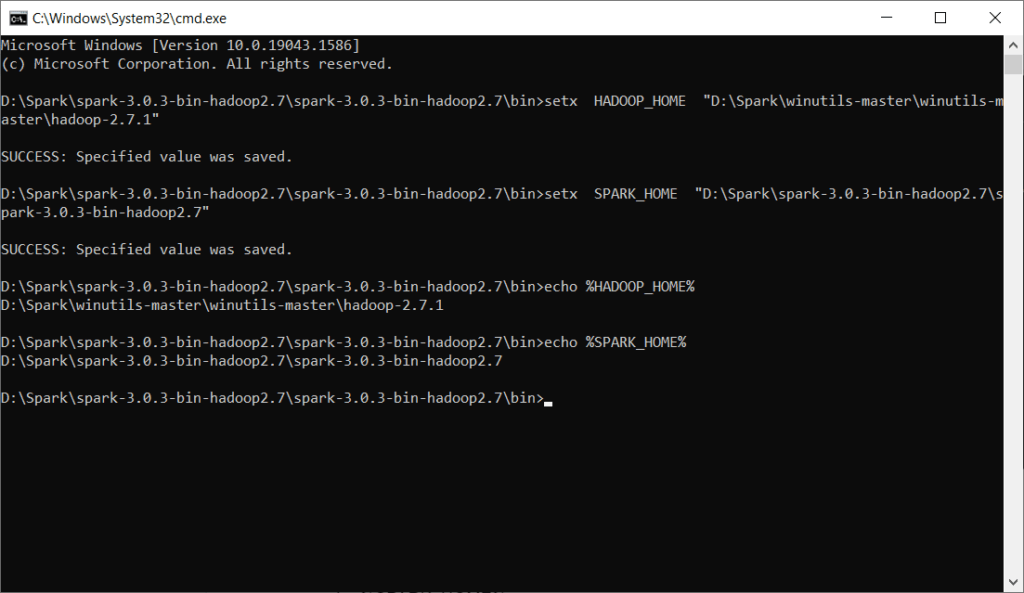
Close the command prompt
Step 17) Again open CMD with path D:\Spark\spark-3.0.3-bin-hadoop2.7\spark-3.0.3-bin-hadoop2.7\bin
Type spark-shell.cmd and press enter
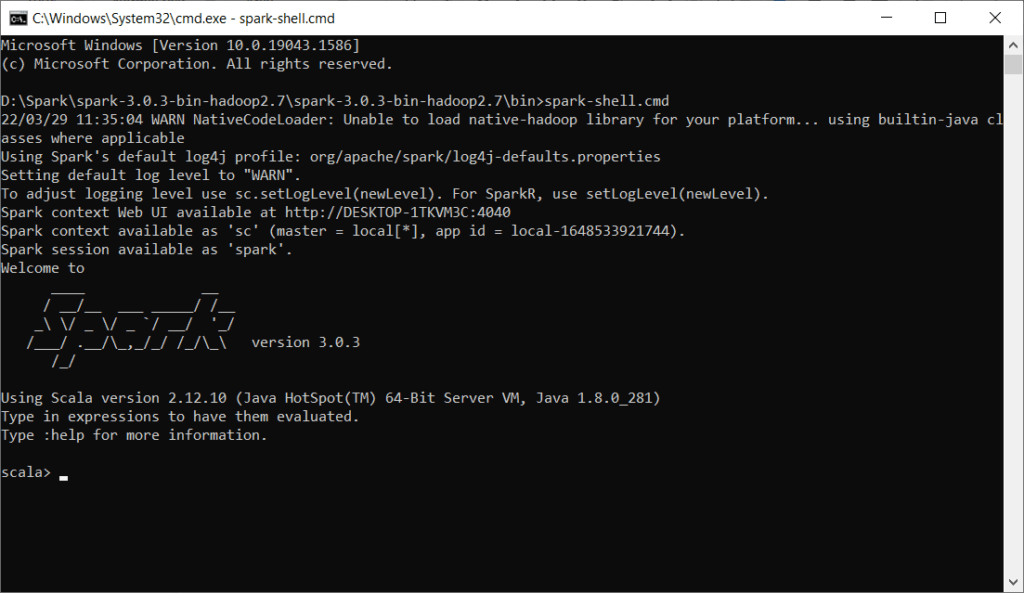
Spark is up and running
Step 18) Perform a quick computation

