
Project idea – The idea behind this ML project is to build a model for a Loan Prediction Based on Customer Behavior and determine the risk factor.
Problem Statement or Business Problem
About Company
Wonderful Dream Housing Finance company deals in all home loans. this ML project is to build a model for a Loan Prediction Based on Customer Behavior
Problem
Company wants to automate the loan risk factor based on customer detail behavior. A loan default occurs when a borrower takes money from a bank and does not repay the loan. Details are Income, Age, Experience, Married/Single, House_Ownership, Car Ownership, Profession, City, State, Current_Job_Yrs, Current House Yrs, and Risk factor. To automate this process, they have given a problem to identify the customer’s behavior and we need to determine the risk factor whether they will be able to pay or become defaulter.
Attribute Information or Dataset Details:
- Id: integer (nullable = true)
- Income: integer (nullable = true)
- Age: integer (nullable = true)
- Experience: integer (nullable = true)
- Married/Single: string (nullable = true)
- House_Ownership: string (nullable = true)
- Car_Ownership: string (nullable = true)
- Profession: string (nullable = true)
- CITY: string (nullable = true)
- STATE: string (nullable = true)
- CURRENT_JOB_YRS: integer (nullable = true)
- CURRENT_HOUSE_YRS: integer (nullable = true)
- Risk_Flag: integer (nullable = true)
Technology Used
- Apache Spark
- Spark SQL
- Apache Spark MLLib
- Scala
- DataFrame-based API
- Databricks Notebook
Introduction
Welcome to this project on Loan Prediction Based on Customer Behavior in Apache Spark Machine Learning using Databricks platform community edition server which allows you to execute your spark code, free of cost on their server just by registering through email id.
In this project, we explore Apache Spark and Machine Learning on the Databricks platform.
I am a firm believer that the best way to learn is by doing. That’s why I haven’t included any purely theoretical lectures in this tutorial: you will learn everything on the way and be able to put it into practice straight away. Seeing the way each feature works will help you learn Apache Spark machine learning thoroughly by heart.
We’re going to look at how to set up a Spark Cluster and get started with that. And we’ll look at how we can then use that Spark Cluster to take data coming into that Spark Cluster, a process that data using a Machine Learning model, and generate some sort of output in the form of a prediction. That’s pretty much what we’re going to learn about the predictive model.
In this project, we will be performing Loan Prediction Based on Customer Behavior
We will learn:
- Preparing the Data for Processing.
- Basics flow of data in Apache Spark, loading data, and working with data, this course shows you how Apache Spark is perfect for a Machine Learning job.
- Learn the basics of Databricks notebook by enrolling in Free Community Edition Server
- Define the Machine Learning Pipeline
- Train a Machine Learning Model
- Testing a Machine Learning Model
- Evaluating a Machine Learning Model (i.e. Examine the Predicted and Actual Values)
- The goal is to provide you with practical tools that will be beneficial for you in the future. While doing that, you’ll develop a model with a real use opportunity.
I am really excited you are here, I hope you are going to follow all the way to the end of the Project. It is fairly straight forward fairly easy to follow through the article we will show you step by step each line of code & we will explain what it does and why we are doing it.
Free Account creation in Databricks
Creating a Spark Cluster
Basics about Databricks notebook
Loading Data into Databricks Environment
Download Data
Load Data in Dataframe
// File location and type
val file_location = "/FileStore/tables/Training_Data.csv"
val file_type = "csv"
// CSV options
val infer_schema = "true"
val first_row_is_header = "true"
val delimiter = ","
// The applied options are for CSV files. For other file types, these will be ignored.
val loanDF = spark.read.format(file_type)
.option("inferSchema", infer_schema)
.option("header", first_row_is_header)
.option("sep", delimiter)
.load(file_location)
display(loanDF)

Print Schema of Dataframe
loanDF.printSchema()
root
|-- Id: integer (nullable = true)
|-- Income: integer (nullable = true)
|-- Age: integer (nullable = true)
|-- Experience: integer (nullable = true)
|-- Married/Single: string (nullable = true)
|-- House_Ownership: string (nullable = true)
|-- Car_Ownership: string (nullable = true)
|-- Profession: string (nullable = true)
|-- CITY: string (nullable = true)
|-- STATE: string (nullable = true)
|-- CURRENT_JOB_YRS: integer (nullable = true)
|-- CURRENT_HOUSE_YRS: integer (nullable = true)
|-- Risk_Flag: integer (nullable = true)
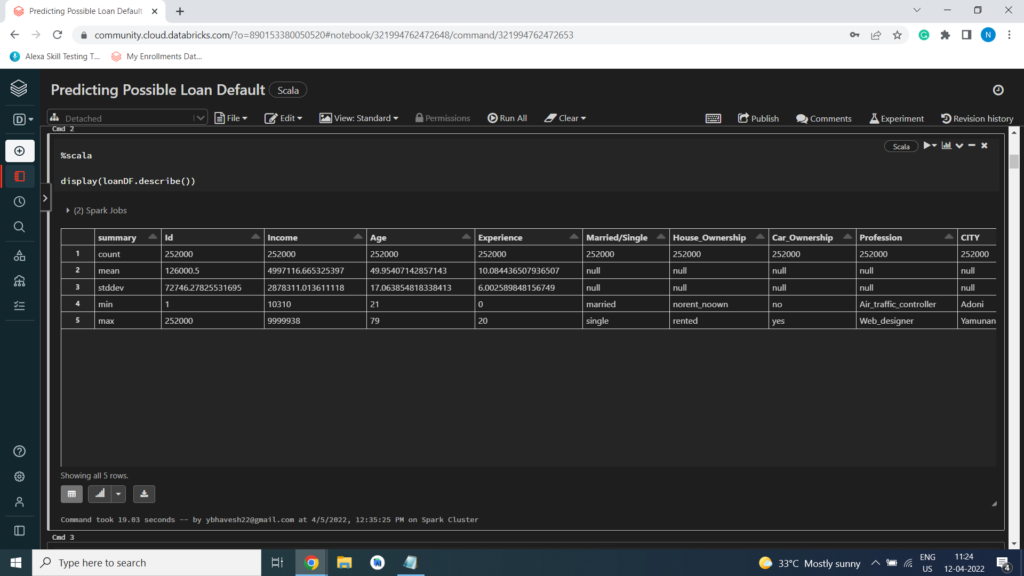
Statistics of Data
display(loanDF.describe())
Exploratory Data Analysis or EDA
Creating Temporary View
loanDF.createOrReplaceTempView("LoanData")

Histogram of Income

Histogram for Age

Histogram for Experience

Histogram of Current Job Yrs

Histogram of Current House Yrs

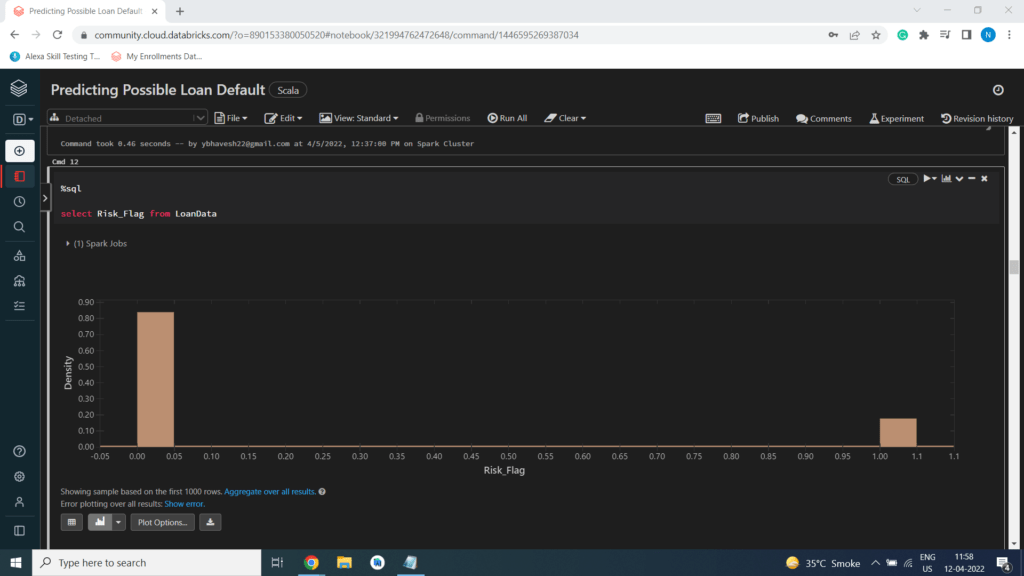
Histogram of Risk Flag
Maritial Status

House Ownership Status

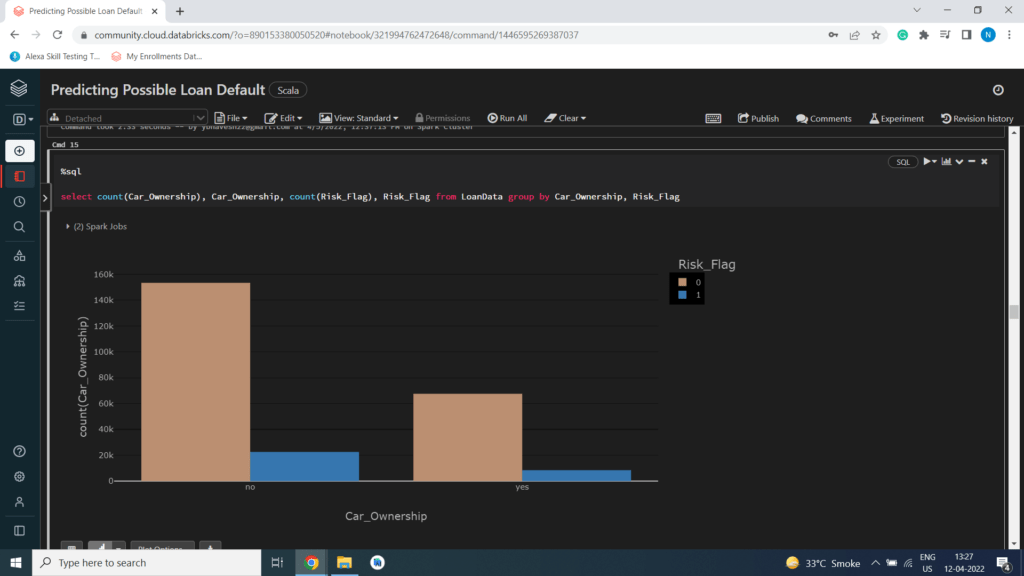
Car Ownership Status
Risk VS Marital Status

Profession Status Count

Income VS Profession


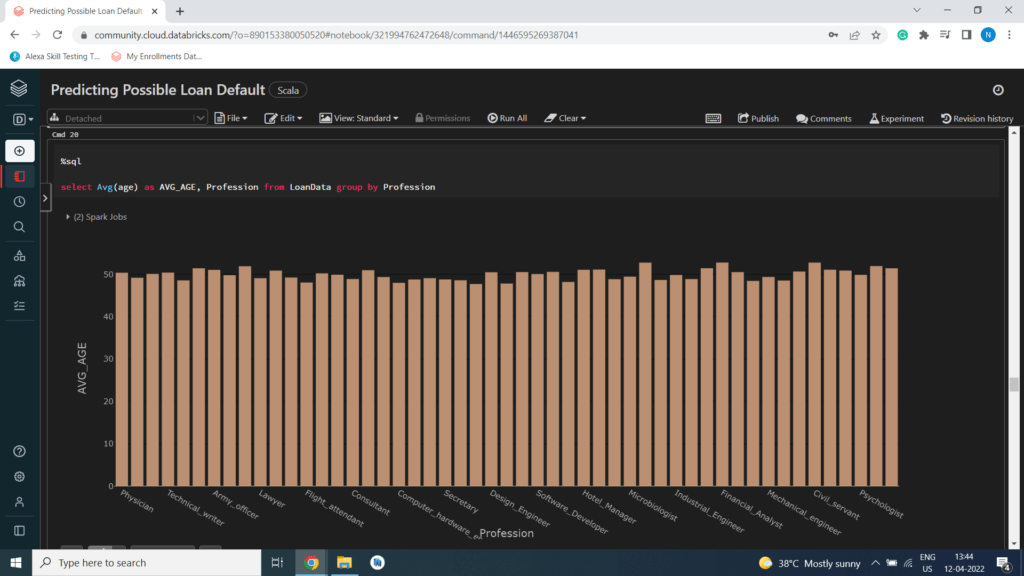
AGE VS PROFESSION
Experience VS Profession

Scatter Plot

Collecting all String Columns into an Array
var StringfeatureCol = Array("Married/Single", "House_Ownership", "Car_Ownership", "Profession", "CITY", "STATE")
StringIndexer encodes a string column of labels to a column of label indices.
Example of StringIndexer
import org.apache.spark.ml.feature.StringIndexer
val df = spark.createDataFrame( Seq((0, “a”), (1, “b”), (2, “c”), (3, “a”), (4, “a”), (5, “c”)) ).toDF(“id”, “category”)
val indexer = new StringIndexer() .setInputCol(“category”) .setOutputCol(“categoryIndex”)
val indexed = indexer.fit(df).transform(df)
display(indexed)

Define the Pipeline
A predictive model often requires multiple stages of feature preparation.
A pipeline consists of a series of transformer and estimator stages that typically prepare a DataFrame for modeling and then train a predictive model.
In this case, you will create a pipeline with stages:
A StringIndexer estimator that converts string values to indexes for categorical features
A VectorAssembler that combines categorical features into a single vector
%scala
import org.apache.spark.ml.attribute.Attribute
import org.apache.spark.ml.feature.{IndexToString, StringIndexer}
import org.apache.spark.ml.{Pipeline, PipelineModel}
val indexers = StringfeatureCol.map { colName =>
new StringIndexer().setInputCol(colName).setHandleInvalid(“skip”).setOutputCol(colName + “_indexed”)
}
val pipeline = new Pipeline()
.setStages(indexers)
val PredictLoanDF = pipeline.fit(loanDF).transform(loanDF)
Split the Data
Split the Data
It is common practice when building machine learning models to split the source data, using some of it to train the model and reserving some to test the trained model. In this project, you will use 70% of the data for training, and reserve 30% for testing.
%scala
val splits = PredictLoanDF.randomSplit(Array(0.7, 0.3))
val train = splits(0)
val test = splits(1)
val train_rows = train.count()
val test_rows = test.count()
println(“Training Rows: ” + train_rows + ” Testing Rows: ” + test_rows)
Prepare the Training Data
To train the Classification model, you need a training data set that includes a vector of numeric features, and a label column. In this project, you will use the VectorAssembler class to transform the feature columns into a vector, and then rename the Risk Status column to the label.
VectorAssembler()
VectorAssembler(): is a transformer that combines a given list of columns into a single vector column. It is useful for combining raw features and features generated by different feature transformers into a single feature vector, in order to train ML models like logistic regression and decision trees.
VectorAssembler accepts the following input column types: all numeric types, boolean type, and vector type.
In each row, the values of the input columns will be concatenated into a vector in the specified order.
%scala
import org.apache.spark.ml.feature.VectorAssembler
val assembler = new VectorAssembler().setInputCols(Array(“Id”, “Income”, “Age”, “Experience”, “Married/Single_indexed”, “House_Ownership_indexed”, “Car_Ownership_indexed”, “CURRENT_JOB_YRS”, “CURRENT_HOUSE_YRS”)).setOutputCol(“features”)
val training = assembler.transform(train).select($”features”, $”Risk_Flag”.alias(“label”))
training.show()

Train a Classification Model
Next, you need to train a Classification model using the training data. To do this, create an instance of the LogisticRegression algorithm you want to use and use its fit method to train a model based on the training DataFrame. In this project, you will use a Logistic Regression Classifier algorithm – though you can use the same technique for any of the regression algorithms supported in the spark.ml API
%scala
import org.apache.spark.ml.classification.DecisionTreeClassificationModel
import org.apache.spark.ml.classification.DecisionTreeClassifier
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
val dt = new DecisionTreeClassifier().setLabelCol(“label”).setFeaturesCol(“features”)
val model = dt.fit(training)
println(“Model Trained!”)
Prepare the Testing Data
Prepare the Testing Data
Now that you have a trained model, you can test it using the testing data you reserved previously. First, you need to prepare the testing data in the same way as you did the training data by transforming the feature columns into a vector. This time you’ll rename the Loan_Status_indexed column to trueLabel.
%scala
val testing = assembler.transform(test).select($”features”, $”Risk_Flag”.alias(“trueLabel”))
testing.show()
Test the Model
Now you’re ready to use the transform method of the model to generate some predictions. You can use this approach to predict the loan status; but in this case, you are using the test data which includes a known true label value, so you can compare the Risk status
%scala
val prediction = model.transform(testing)
val predicted = prediction.select(“features”, “prediction”, “trueLabel”)
display(predicted)

Evaluating a Model (We got 87% Accuracy)
%scala
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol(“trueLabel”)
.setPredictionCol(“prediction”)
.setMetricName(“accuracy”)
val accuracy = evaluator.evaluate(prediction)
Output
accuracy: Double = 0.878602781744143

