Use the following property in the respective files
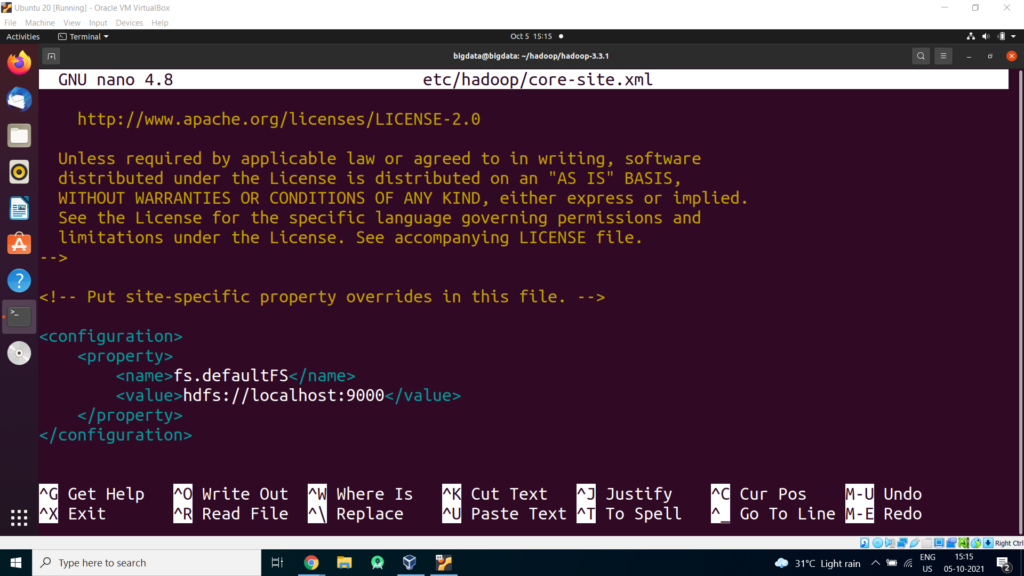
File: nano etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
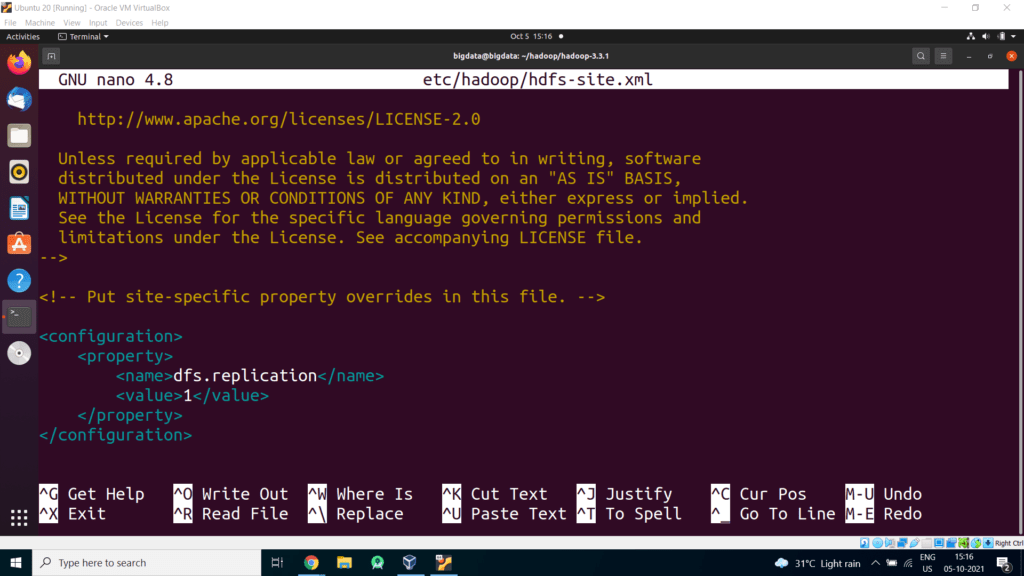
File: nano etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
File: nano etc/hadoop/mapred-site.xml
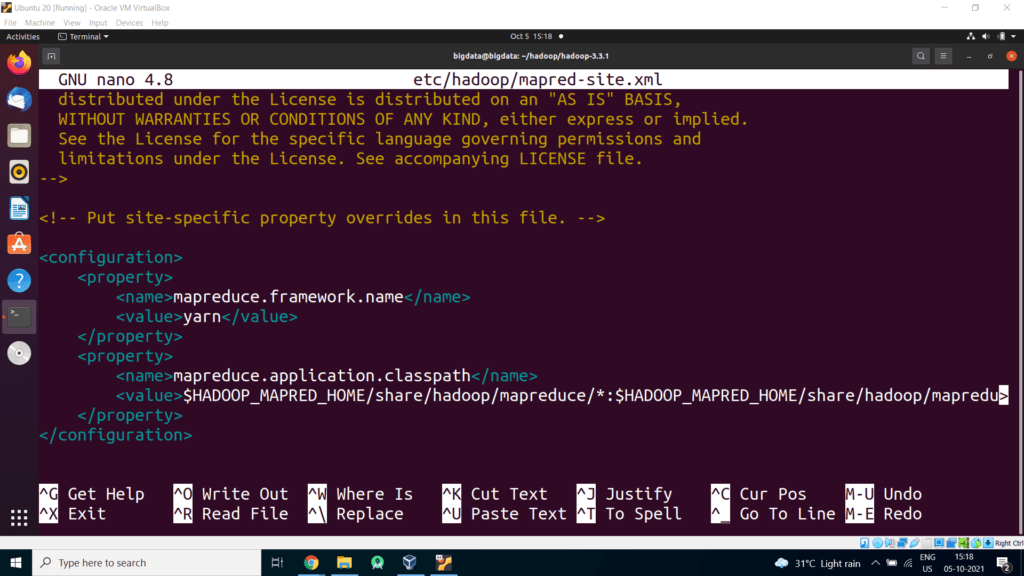
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value> $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
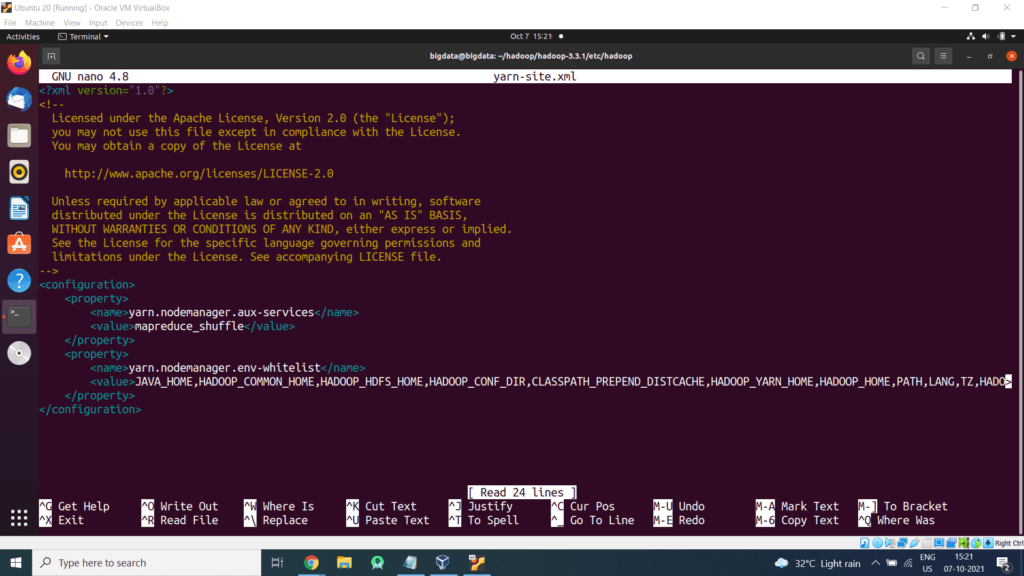
File: nano etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value> JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,
HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME*</value>
</property>
</configuration>
Now check that you can ssh to the localhost without a passphrase:
If you cannot ssh to localhost without a passphrase, execute the following commands:
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
Open the bashrc files in the nano editor using the following command:
edit .bashrc file located in the user’s home directory and add the following parameters:
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export YARN_HOME=${HADOOP_HOME}

To save the changes you’ve made, press Ctrl+O. To exit the nano editor, press Ctrl+X and then press ‘Y’ to exit the editor.
Now, source the bashrc file so that the changes will come into effect:
Format the filesystem:
Start NameNode daemon and DataNode daemon:
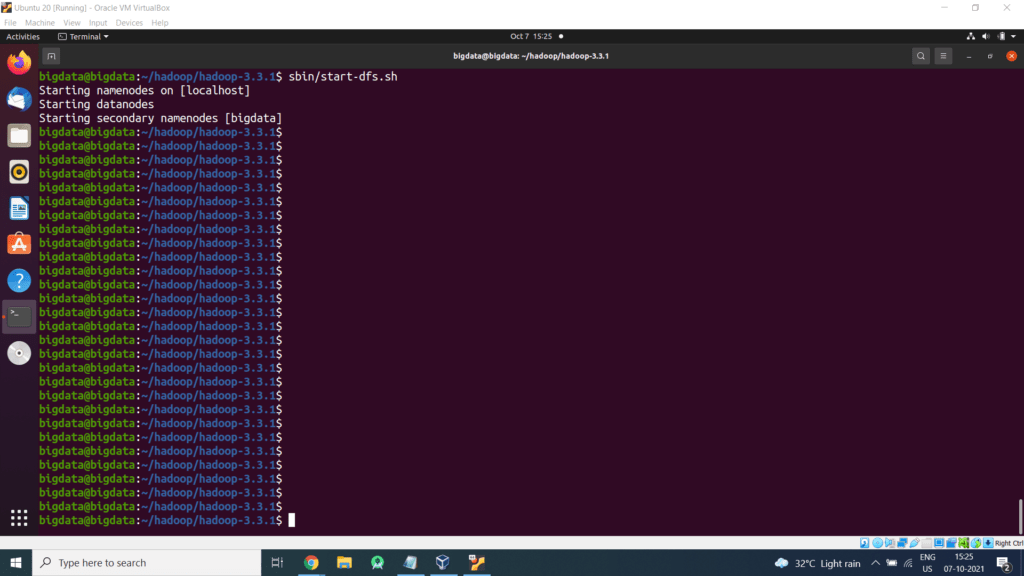
The hadoop daemon log output is written to the $HADOOP_LOG_DIR directory (defaults to $HADOOP_HOME/logs).
Browse the web interface for the NameNode; by default it is available at:
NameNode – http://localhost:9870/

Start ResourceManager daemon and NodeManager daemon:

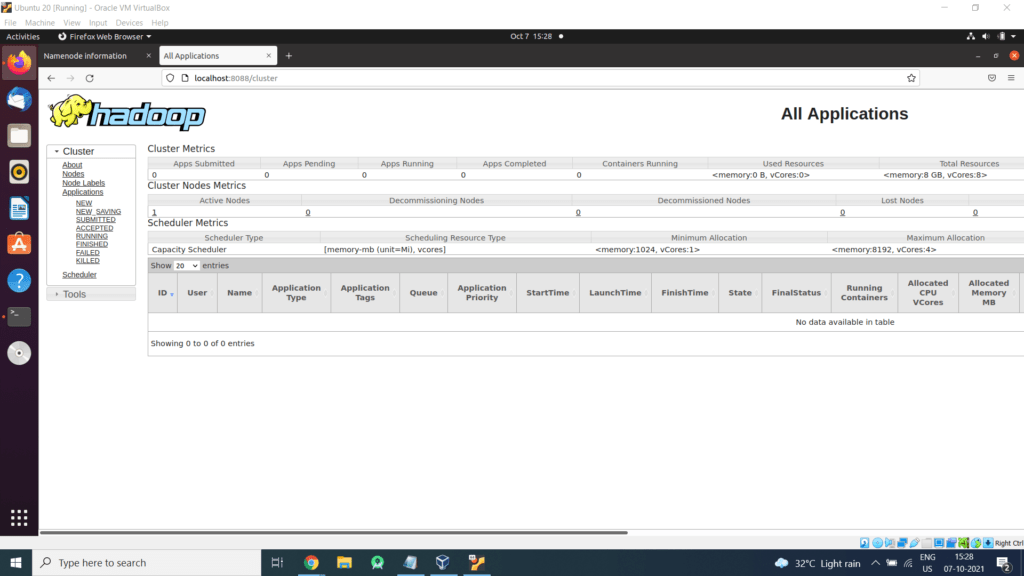
Browse the web interface for the ResourceManager; by default it is available at:
ResourceManager – http://localhost:8088/