Machine Learning Project to predict whether a person makes over 50K a year

Problem Statement or Business Problem
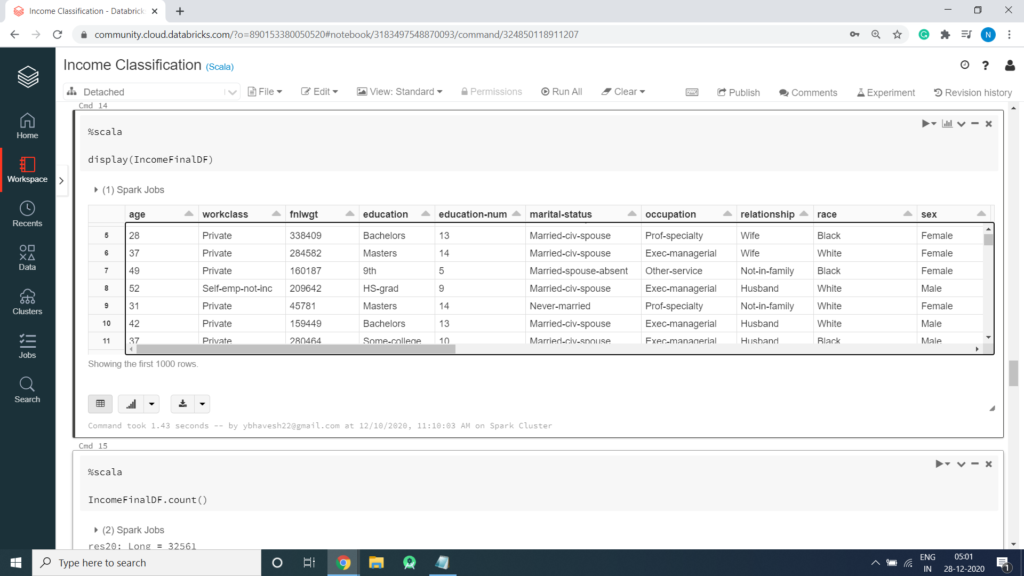
Prediction task is to determine whether a person makes over 50K a year.(Income Classification)
Attribute Information or Dataset Details:
age: integer
workclass: string
fnlwgt: integer
education: string
education-num: integer
marital-status: string
occupation: string
relationship: string
race: string
sex: string
capital-gain: integer
capital-loss: integer
hours-per-week: integer
native-country: string
income: string

Technology Used
- Apache Spark
- Spark SQL
- Apache Spark MLLib
- Scala
- DataFrame-based API
- Databricks Notebook
Challenges
Convert String data to Numeric format so we can process the data in Apache Spark ML Library.
Introduction
Welcome to this project on predict whether a person makes over 50K a year in Apache Spark Machine Learning using Databricks platform community edition server which allows you to execute your spark code, free of cost on their server just by registering through email id.
In this project we explore Apache Spark and Machine Learning on the Databricks platform.
I am a firm believer that the best way to learn is by doing. That’s why I haven’t included any purely theoretical lectures in this tutorial: you will learn everything on the way and be able to put it into practice straight away. Seeing the way each feature works will help you learn Apache Spark machine learning thoroughly by heart.
We’re going to look at how to set up a Spark Cluster and get started with that. And we’ll look at how we can then use that Spark Cluster to take data coming into that Spark Cluster, process that data using a Machine Learning model, and generate some sort of output in the form of a prediction. That’s pretty much what we’re going to learn about predictive model.
In this project we will be Predict whether a person makes over 50K a year using Linear Regression algorithm.
We will learn:
- Preparing the Data for Processing.
- Basics flow of data in Apache Spark, loading data, and working with data, this course shows you how Apache Spark is perfect for Machine Learning job.
- Learn basics of Databricks notebook by enrolling into Free Community Edition Server
- Define the Machine Learning Pipeline
- Train a Machine Learning Model
- Testing a Machine Learning Model
- Evaluating a Machine Learning Model (i.e. Examine the Predicted and Actual Values)
The Goal is to provide you with practical tools that will be beneficial for you in the future. While doing that, you’ll develop a model with a real use opportunity.
I am really excited you are here, I hope you are going to follow all the way to the end of the Project. It is fairly straight forward fairly easy to follow through the article we will show you step by step each line of code & we will explain what it does and why we are doing it.
Free Account creation in Databricks
Creating a Spark Cluster
Basics about Databricks notebook
Loading Data into Databricks Environment
Download Data
Load Data in Dataframe
%scala
val csv = spark.read.option("inferSchema","true").option("header", "true").csv("/FileStore/tables/income_evaluation-1.csv")
csv.show()
Output:
+---+-----------------+------+-------------+-------------+--------------------+------------------+--------------+-------------------+-------+------------+------------+--------------+--------------+------+
|age| workclass|fnlwgt| education|education-num| marital-status| occupation| relationship| race| sex|capital-gain|capital-loss|hours-per-week|native-country|income|
+---+-----------------+------+-------------+-------------+--------------------+------------------+--------------+-------------------+-------+------------+------------+--------------+--------------+------+
| 39| State-gov| 77516| Bachelors| 13| Never-married| Adm-clerical| Not-in-family| White| Male| 2174| 0| 40| United-States| <=50K|
| 50| Self-emp-not-inc| 83311| Bachelors| 13| Married-civ-spouse| Exec-managerial| Husband| White| Male| 0| 0| 13| United-States| <=50K|
| 38| Private|215646| HS-grad| 9| Divorced| Handlers-cleaners| Not-in-family| White| Male| 0| 0| 40| United-States| <=50K|
| 53| Private|234721| 11th| 7| Married-civ-spouse| Handlers-cleaners| Husband| Black| Male| 0| 0| 40| United-States| <=50K|
| 28| Private|338409| Bachelors| 13| Married-civ-spouse| Prof-specialty| Wife| Black| Female| 0| 0| 40| Cuba| <=50K|
| 37| Private|284582| Masters| 14| Married-civ-spouse| Exec-managerial| Wife| White| Female| 0| 0| 40| United-States| <=50K|
| 49| Private|160187| 9th| 5| Married-spouse-a...| Other-service| Not-in-family| Black| Female| 0| 0| 16| Jamaica| <=50K|
| 52| Self-emp-not-inc|209642| HS-grad| 9| Married-civ-spouse| Exec-managerial| Husband| White| Male| 0| 0| 45| United-States| >50K|
| 31| Private| 45781| Masters| 14| Never-married| Prof-specialty| Not-in-family| White| Female| 14084| 0| 50| United-States| >50K|
| 42| Private|159449| Bachelors| 13| Married-civ-spouse| Exec-managerial| Husband| White| Male| 5178| 0| 40| United-States| >50K|
| 37| Private|280464| Some-college| 10| Married-civ-spouse| Exec-managerial| Husband| Black| Male| 0| 0| 80| United-States| >50K|
| 30| State-gov|141297| Bachelors| 13| Married-civ-spouse| Prof-specialty| Husband| Asian-Pac-Islander| Male| 0| 0| 40| India| >50K|
| 23| Private|122272| Bachelors| 13| Never-married| Adm-clerical| Own-child| White| Female| 0| 0| 30| United-States| <=50K|
| 32| Private|205019| Assoc-acdm| 12| Never-married| Sales| Not-in-family| Black| Male| 0| 0| 50| United-States| <=50K|
| 40| Private|121772| Assoc-voc| 11| Married-civ-spouse| Craft-repair| Husband| Asian-Pac-Islander| Male| 0| 0| 40| ?| >50K|
| 34| Private|245487| 7th-8th| 4| Married-civ-spouse| Transport-moving| Husband| Amer-Indian-Eskimo| Male| 0| 0| 45| Mexico| <=50K|
| 25| Self-emp-not-inc|176756| HS-grad| 9| Never-married| Farming-fishing| Own-child| White| Male| 0| 0| 35| United-States| <=50K|
| 32| Private|186824| HS-grad| 9| Never-married| Machine-op-inspct| Unmarried| White| Male| 0| 0| 40| United-States| <=50K|
| 38| Private| 28887| 11th| 7| Married-civ-spouse| Sales| Husband| White| Male| 0| 0| 50| United-States| <=50K|
| 43| Self-emp-not-inc|292175| Masters| 14| Divorced| Exec-managerial| Unmarried| White| Female| 0| 0| 45| United-States| >50K|
+---+-----------------+------+-------------+-------------+--------------------+------------------+--------------+-------------------+-------+------------+------------+--------------+--------------+------+
only showing top 20 rowsPrinting Schema of Dataframe
%scala csv.printSchema() Output: root |-- age: integer (nullable = true) |-- workclass: string (nullable = true) |-- fnlwgt: integer (nullable = true) |-- education: string (nullable = true) |-- education-num: integer (nullable = true) |-- marital-status: string (nullable = true) |-- occupation: string (nullable = true) |-- relationship: string (nullable = true) |-- race: string (nullable = true) |-- sex: string (nullable = true) |-- capital-gain: integer (nullable = true) |-- capital-loss: integer (nullable = true) |-- hours-per-week: integer (nullable = true) |-- native-country: string (nullable = true) |-- income: string (nullable = true)
Get Statistics of Data
%scala
csv.select("age", "workclass", "fnlwgt", "education", "education-num", "marital-status", "occupation", "relationship","race", "sex", "capital-gain", "capital-loss","hours-per-week", "native-country", "income" ).describe().show()
Output:
+-------+------------------+------------+------------------+-------------+-----------------+--------------+-----------------+------------+-------------------+-------+------------------+----------------+------------------+--------------+------+
|summary| age| workclass| fnlwgt| education| education-num|marital-status| occupation|relationship| race| sex| capital-gain| capital-loss| hours-per-week|native-country|income|
+-------+------------------+------------+------------------+-------------+-----------------+--------------+-----------------+------------+-------------------+-------+------------------+----------------+------------------+--------------+------+
| count| 32561| 32561| 32561| 32561| 32561| 32561| 32561| 32561| 32561| 32561| 32561| 32561| 32561| 32561| 32561|
| mean| 38.58164675532078| null|189778.36651208502| null| 10.0806793403151| null| null| null| null| null|1077.6488437087312| 87.303829734959|40.437455852092995| null| null|
| stddev|13.640432553581356| null|105549.97769702227| null|2.572720332067397| null| null| null| null| null| 7385.292084840354|402.960218649002|12.347428681731838| null| null|
| min| 17| ?| 12285| 10th| 1| Divorced| ?| Husband| Amer-Indian-Eskimo| Female| 0| 0| 1| ?| <=50K|
| max| 90| Without-pay| 1484705| Some-college| 16| Widowed| Transport-moving| Wife| White| Male| 99999| 4356| 99| Yugoslavia| >50K|
+-------+------------------+------------+------------------+-------------+-----------------+--------------+-----------------+------------+-------------------+-------+------------------+----------------+------------------+--------------+------+Creating Temporary View in Spark so that we can use Spark SQL to Analyze the Data
%scala
csv.createOrReplaceTempView("IncomeData");
Generate Graph
%sql select Sex, count(Sex) from IncomeData group by Sex

Collecting all String Columns into an Array
%scala
var StringfeatureCol = Array("workclass", "education", "marital-status", "occupation", "relationship", "race", "sex", "native-country", "income");StringIndexer encodes a string column of labels to a column of label indices.
Example of StringIndexer
%scala
import org.apache.spark.ml.feature.StringIndexer
val df = spark.createDataFrame(
Seq((0, "a"), (1, "b"), (2, "c"), (3, "a"), (4, "a"), (5, "c"))
).toDF("id", "category")
df.show()
val indexer = new StringIndexer()
.setInputCol("category")
.setOutputCol("categoryIndex")
val indexed = indexer.fit(df).transform(df)
indexed.show()
Output:
+---+--------+
| id|category|
+---+--------+
| 0| a|
| 1| b|
| 2| c|
| 3| a|
| 4| a|
| 5| c|
+---+--------+
+---+--------+-------------+
| id|category|categoryIndex|
+---+--------+-------------+
| 0| a| 0.0|
| 1| b| 2.0|
| 2| c| 1.0|
| 3| a| 0.0|
| 4| a| 0.0|
| 5| c| 1.0|
+---+--------+-------------+Define the Pipeline
A predictive model often requires multiple stages of feature preparation.
A pipeline consists of a series of transformer and estimator stages that typically prepare a DataFrame for modeling and then train a predictive model.
In this case, you will create a pipeline with stages:
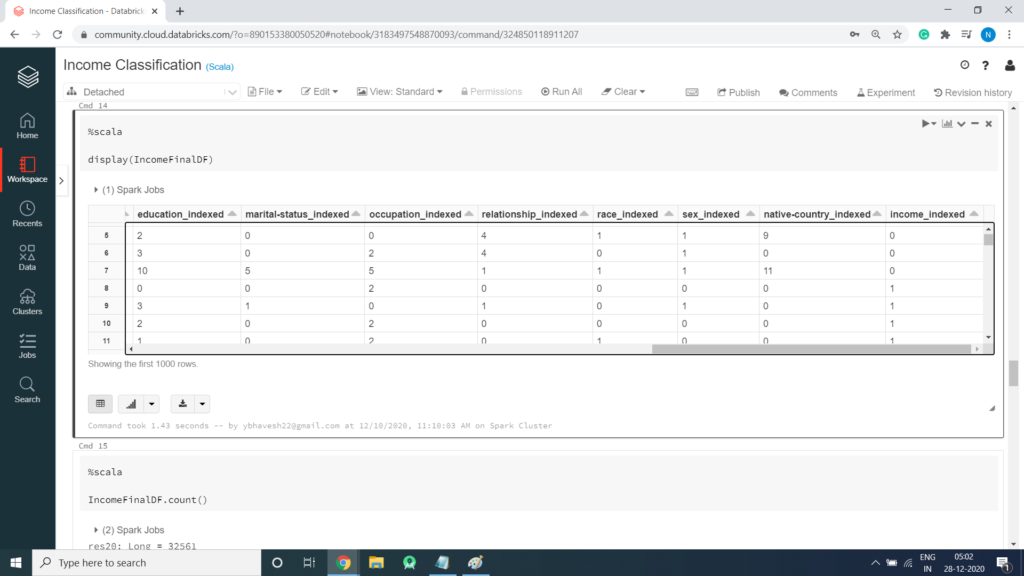
- A StringIndexer estimator that converts string values to indexes for categorical features
- A VectorAssembler that combines categorical features into a single vector
%scala
import org.apache.spark.ml.attribute.Attribute
import org.apache.spark.ml.feature.{IndexToString, StringIndexer}
import org.apache.spark.ml.{Pipeline, PipelineModel}
val indexers = StringfeatureCol.map { colName =>
new StringIndexer().setInputCol(colName).setHandleInvalid("skip").setOutputCol(colName + "_indexed")
}
val pipeline = new Pipeline()
.setStages(indexers)
val IncomeFinalDF = pipeline.fit(csv).transform(csv)Print Schema to view String Columns are converted in to equivalent Numerical Columns
%scala IncomeFinalDF.printSchema() Output: root |-- age: integer (nullable = true) |-- workclass: string (nullable = true) |-- fnlwgt: integer (nullable = true) |-- education: string (nullable = true) |-- education-num: integer (nullable = true) |-- marital-status: string (nullable = true) |-- occupation: string (nullable = true) |-- relationship: string (nullable = true) |-- race: string (nullable = true) |-- sex: string (nullable = true) |-- capital-gain: integer (nullable = true) |-- capital-loss: integer (nullable = true) |-- hours-per-week: integer (nullable = true) |-- native-country: string (nullable = true) |-- income: string (nullable = true) |-- workclass_indexed: double (nullable = false) |-- education_indexed: double (nullable = false) |-- marital-status_indexed: double (nullable = false) |-- occupation_indexed: double (nullable = false) |-- relationship_indexed: double (nullable = false) |-- race_indexed: double (nullable = false) |-- sex_indexed: double (nullable = false) |-- native-country_indexed: double (nullable = false) |-- income_indexed: double (nullable = false)
Display Data