In this article, We will see how to process Sensex Log (Share Market) which is in PDF format using Big Data Technology, We will see step by step process execution of the project.

Problem Statement: Analyse the data in Hadoop Eco-system to:
- Take the complete PDF Input data on HDFS
- Develop a Map-Reduce Use Case to get the below-filtered results from the HDFS Input data(Excel data)
If TYPE OF TRADING is –>’SIP’
– OPEN_BALANCE > 25000 & FLTUATION_RATE > 10 –> store “HighDemandMarket”
-CLOSING_BALANCE<22000 & FLTUATION_RATE IN BETWEEN 20 – 30 –> store “OnGoingMarketStretegy”
If TYPE OF TRADING is –>’SHORTTERM
– OPEN_BALANCE < 5000 –> store “WealthyProducts”
– SensexLoc –> “NewYork OR Mumbai” –> “ReliableProducts
else
store in “OtherProducts”
NOTE: In the mentioned file names only 5 outputs have to be generated
- Develop a PIG Script to filter the Map Reduce Output in the below fashion
– Provide the Unique data
– Sort the Unique data based on SensexID.
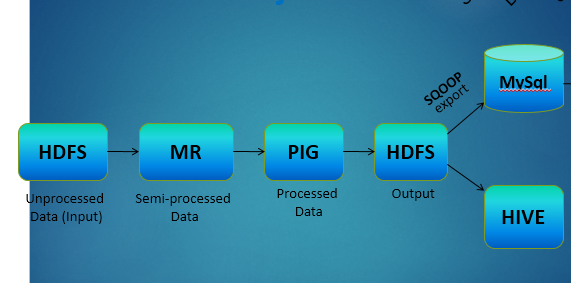
- EXPORT the same PIG Output from HDFS to MySQL using SQOOP
- Store the same PIG Output in a HIVE External Table

Attribute Information or Dataset Details:
| column | Description |
|---|---|
| 1 | SENSEXID |
| 2 | SENSEXNAME |
| 3 | TYPEOFTRADING |
| 4 | SENSEXLOC |
| 5 | OPEN_BALANCE |
| 6 | CLOSING_BAL |
| 7 | FLTUATION_RATE |
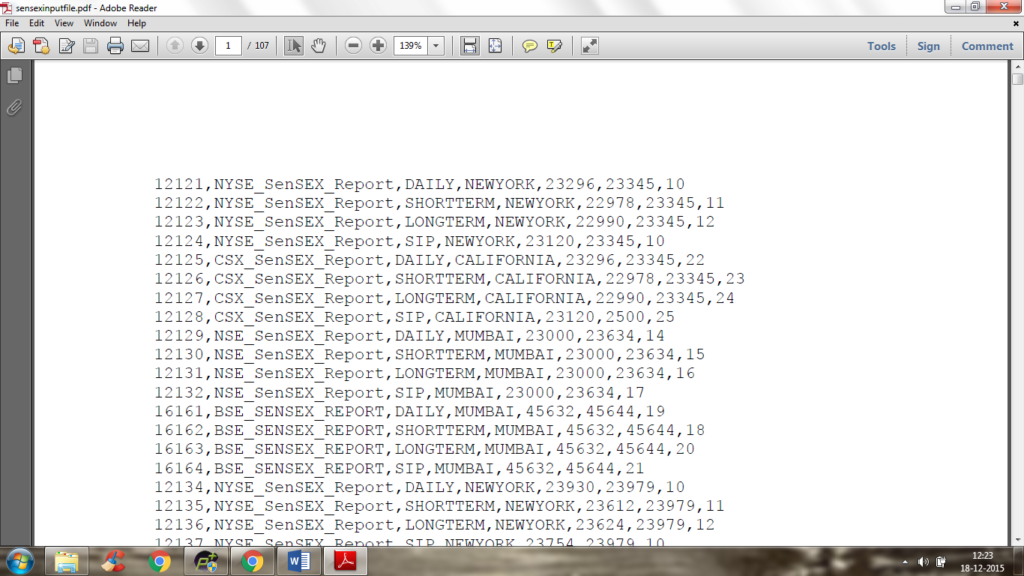
Data: Input Format – .PDF (Our Input Data is in PDF Format)
Like this below created 3000 records on my own
Technology Used
- Apache Hadoop (HDFS)
- Mapreduce
- Apache Pig
- Apache Hive
- MySQL
- Shell Script
- Apache Sqoop
- Linux
- Java
Flow Chart
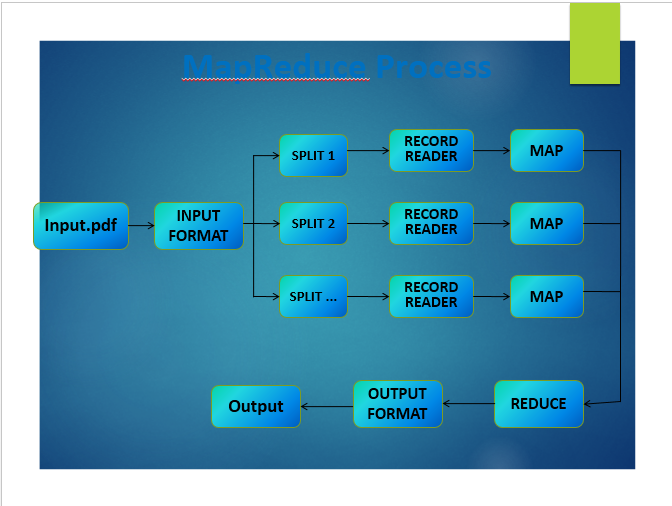
Mapreduce Process
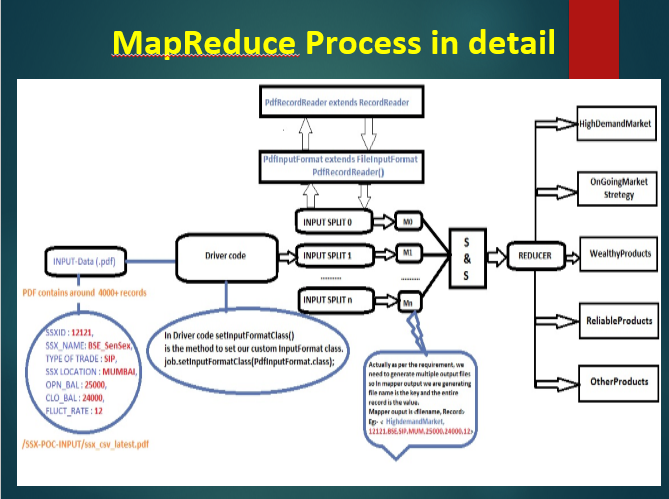
Mapreduce Code
PdfInputDriver.java
package com.bhavesh.poc.sensex;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.LazyOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class PdfInputDriver {
public static void main(String[] args) throws IOException,
InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
//GenericOptionsParser is a utility to parse command line arguments generic to the Hadoop framework
GenericOptionsParser parser = new GenericOptionsParser(conf, args);
//Returns an array of Strings containing only application-specific arguments
args = parser.getRemainingArgs();
Job job = new Job(conf, "PdfSensexDetails");
job.setJarByClass(PdfInputDriver.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// Custom InputFormat class
job.setInputFormatClass(PdfInputFormat.class);
//job.setOutputFormatClass(TextOutputFormat.class);
LazyOutputFormat.setOutputFormatClass(job, TextOutputFormat.class);
MultipleOutputs.addNamedOutput(job, "text", TextOutputFormat.class,IntWritable.class, Text.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(SensexTradeMapper.class);
job.setReducerClass(SensexTradeReducer.class);
System.out.println(job.waitForCompletion(true));
}
}PdfInputFormat.java
package com.bhavesh.poc.sensex;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
public class PdfInputFormat extends FileInputFormat {
@Override
public RecordReader createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException,
InterruptedException {
return new PdfRecordReader();
}
}
PdfRecordReader.java
package com.bhavesh.poc.sensex;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.util.PDFTextStripper;
public class PdfRecordReader extends RecordReader{
private String[] lines = null;
private LongWritable key = null;
private Text value = null;
@Override
public void initialize(InputSplit genericSplit, TaskAttemptContext context)
throws IOException, InterruptedException {
FileSplit split = (FileSplit) genericSplit;
Configuration job = context.getConfiguration();
final Path file = split.getPath();
/*
* The below code contains the logic for opening the file and seek to
* the start of the split. Here we are applying the Pdf Parsing logic
*/
FileSystem fs = file.getFileSystem(job);
FSDataInputStream fileIn = fs.open(split.getPath());
PDDocument pdf = null;
String parsedText = null;
PDFTextStripper stripper; // Here we are coverting PDF to textinputformate
pdf = PDDocument.load(fileIn);
stripper = new PDFTextStripper();
parsedText = stripper.getText(pdf);
this.lines = parsedText.split("\n");
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if (key == null) {
key = new LongWritable();
key.set(1);
value = new Text();
value.set(lines[0]);
} else {
int temp = (int) key.get();
if (temp < (lines.length - 1)) {
int count = (int) key.get();
value = new Text();
value.set(lines[count]);
count = count + 1;
key = new LongWritable(count);
} else {
return false;
}
}
if (key == null || value == null) {
return false;
} else {
return true;
}
}
@Override
public LongWritable getCurrentKey() throws IOException,
InterruptedException {
return key;
}
@Override
public Text getCurrentValue() throws IOException, InterruptedException {
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return 0;
}
@Override
public void close() throws IOException {
}
}SensexTradeMapper.java
package com.bhavesh.poc.sensex;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class SensexTradeMapper extends Mapper<LongWritable, Text, Text, Text> {
private Text word = new Text();
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String TradeType;
String Location;
int Open_bal;
int Close_bal;
int Fluct_rate;
String str[] = value.toString().split(",");
TradeType =str[2].toString();
Location = str[3].toString();
String Opbal = str[4];
Open_bal = Integer.parseInt(Opbal);
String Clbal = str[5];
Close_bal = Integer.parseInt(Clbal);
String fcrate = str[6].trim();
Fluct_rate = Integer.parseInt(fcrate);
if (TradeType.equals(new String("SIP")))
{
if (Open_bal > 20000 && Fluct_rate <= 15)
{
word.set(new String("HighDemandMarket")); //word == key
}
else if(Close_bal > 30000 && Fluct_rate > 15 && Fluct_rate < 25)
{
word.set(new String("OnGoingMarketStretegy"));
}
}
else if(TradeType.equals(new String("SHORTTERM")))
{
if (Open_bal > 5000 && Open_bal < 30000)
{
word.set(new String("WealthyProducts"));
}
else if((Location.equals(new String("NEWYORK"))) ||
(Location.equals(new String("MUMBAI"))))
{
word.set(new String("ReliableProducts"));
}
}
else
{
word.set(new String("OtherProducts"));
}
String rec = str[0]+"\t"+str[1]+"\t"+str[2]+"\t"+str[3]+"\t"+str[4]+"\t"+str[5]+"\t"+str[6];
//context.progress();
context.write(word, new Text(rec));
}
}SensexTradeReducer.java
package com.poc.ssx;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
public class SensexTradeReducer extends
Reducer<Text, Text, IntWritable, Text> {
private MultipleOutputs<IntWritable, Text> multipleOutputs;
protected void reduce(Text key, Iterable<Text> values,
Context context) throws IOException, InterruptedException {
String str1 = null;
int ssxid = 0;
for (Text value : values) {
String str[] = value.toString().split("\t");
String sxid = str[0].trim();
ssxid = Integer.parseInt(sxid);
str1 = str[1]+"\t"+str[2]+"\t"+str[3]+"\t"+str[4]+"\t"+str[5]+"\t"+str[6];
//context.write(new IntWritable(ssxid), new Text(ssxname+","+TradeType+","+Location+","+Open_bal+","+Close_bal+","+Fluct_rate));
multipleOutputs.write(new IntWritable(ssxid),
new Text(str1),
generateFileName(key));
}
}
String generateFileName(Text key){
return key.toString();
}
@Override
public void setup(Context context){
multipleOutputs = new MultipleOutputs<IntWritable, Text>(context);
}
@Override
public void cleanup(final Context context) throws IOException, InterruptedException{
multipleOutputs.close();
}
}