
Apache Druid is a real-time analytics database designed for fast slice-and-dice analytics on large datasets. Running Druid on Docker Desktop in Windows OS enables data engineers and analysts to spin up a full Druid cluster with minimal configuration. In this blog, we’ll walk through how to get Apache Druid running locally using Docker.
Prerequisites
Before starting, ensure your system meets the following requirements:
Windows 10/11 with WSL 2 enabled
Docker Desktop installed and running
Minimum 8GB RAM (16GB recommended for better performance)
Git Bash or PowerShell for command-line execution
Step 1: Clone the Apache Druid GitHub Repository
Apache Druid provides a quickstart Docker Compose setup in its GitHub repo. Clone it with:
git clone https://github.com/apache/druid.git
cd druid/distribution/docker

Step 2: Start Apache Druid with Docker Compose
Use the included Docker Compose file to launch a micro-cluster with all required services:
docker-compose -f docker-compose.yml up
This command starts the following services:
ZooKeeper
Metadata storage (PostgreSQL)
Coordinator
Overlord
Broker
Historical
Middle Manager
Router
It may take a few minutes for all services to start up.

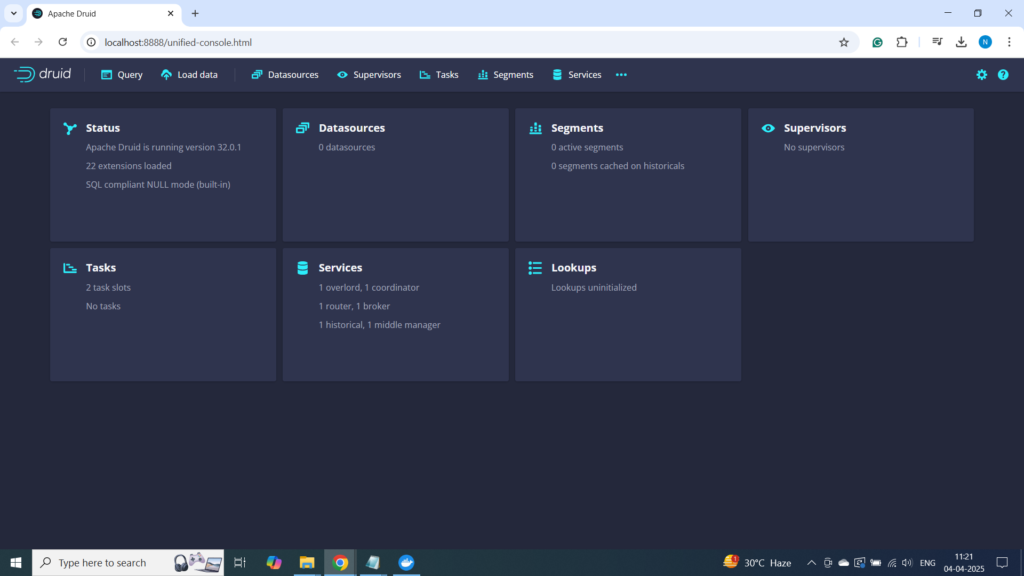
Step 3: Accessing the Druid Console
Once the containers are up, you can access the Druid web console in your browser at:
http://localhost:8888
This is where you can load data, define ingestion specs, and run SQL queries.
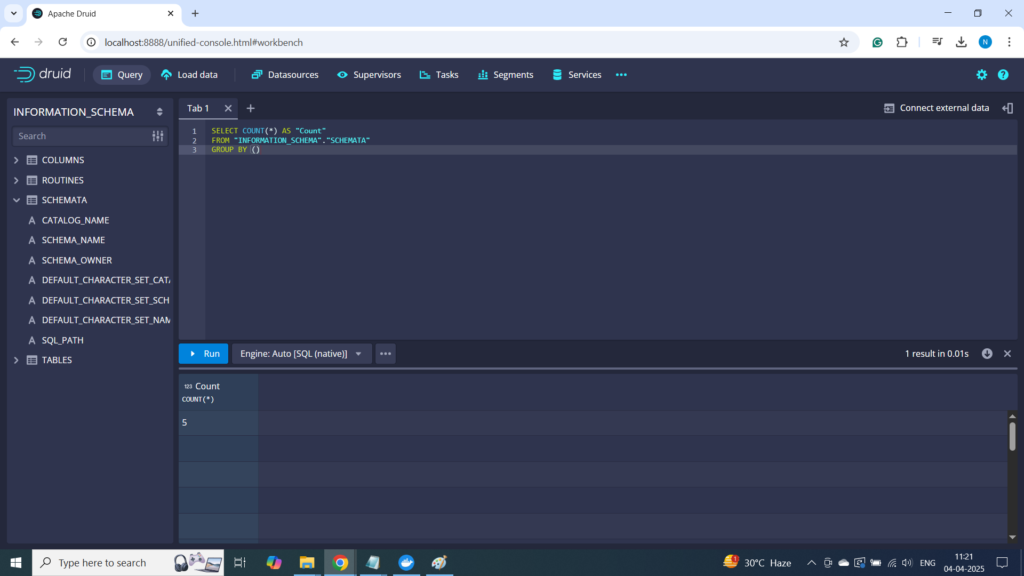
Step 4: Querying Data Using Druid SQL
Druid provides sub-second query response times, even for millions of records.
Step 5: Stopping the Druid Cluster
To shut down all running containers:
docker-compose -f docker-compose.yml down
This stops and removes all containers in the Druid cluster.
Conclusion
Running Apache Druid on Docker Desktop in Windows is a powerful way to prototype real-time analytics solutions without setting up physical infrastructure. Whether you’re testing out new data models or learning Druid’s capabilities, this setup provides a fast and reproducible environment.
Happy exploring with Apache Druid! 🚀
